Chameleon
A dense linear algebra software for heterogeneous architectures
Table of Contents
- 1. Overview
- 2. News
- 3. Download
- 4. Quick start guide
- 5. Documentation
- 5.1. Version
- 5.2. Authors
- 5.3. Copying
- 5.4. Introduction to Chameleon
- 5.5. Installing Chameleon
- 5.5.1. Getting Chameleon
- 5.5.2. Prerequisites for installing Chameleon
- 5.5.3. Build and install Chameleon with CMake
- 5.5.4. Distribution of Chameleon using GNU Guix
- 5.5.5. Distribution of Chameleon using Spack
- 5.5.6. Distribution Brew for Mac OS X
- 5.5.7. Linking an external application with Chameleon libraries
- 5.6. Using Chameleon
- 5.7. Chameleon Performances on PlaFRIM
- 6. Tutorials
- 7. Contact
- 8. Contributing
- 9. Authors
- 10. Citing Chameleon
- 11. Licence
1. Overview
Chameleon is a framework written in C which provides routines to solve dense general systems of linear equations, symmetric positive definite systems of linear equations and linear least squares problems, using LU, Cholesky, QR and LQ factorizations. Real arithmetic and complex arithmetic are supported in both single precision and double precision. It supports Linux and Mac OS/X machines (mainly tested on Intel x86-64 and IBM Power architectures). Chameleon is based on the PLASMA source code but is not limited to shared-memory environment and can exploit multiple GPUs. Chameleon is interfaced in a generic way with StarPU, PaRSEC, QUARK, OpenMP runtime systems. This feature allows to analyze in a unified framework how sequential task-based algorithms behave regarding different runtime systems implementations. Using Chameleon with StarPU runtime systems allows to exploit GPUs through kernels provided by cuBLAS and clusters of interconnected nodes with distributed memory (using MPI).
Main features:
- Written in C, Fortran interface, CMake build system
- Algorithms: GEMM, POTRF, GETRF, GEQRF, GESVD, …
- Matrices forms: general, symmetric, triangular
- Precisions: simple, double, complex, double complex

2. News
- Release 1.3.0 available, see changes, download source tarball.
- Release 1.2.0 available, see changes, download source tarball.
- Added support for HIP and hipblas (CUDA and ROC backend), see MR 355.
- Add parallel kernels support, see MR 206.
- Add A-stationnary GEMM and SYMM algorithms, see MR 334.
- Add a BLAS/LAPACK compatible interface, see MR 332.
- Algorithms: BLAS gemm, hemm, her2k, herk, lauum, symm, syr2k, syrk, trmm, trsm and LAPACK lacpy, lange, lanhe, lansy, lantr, laset, posv, potrf, potri, potrs, trtri
- Add new performance models for Starpu + Simgrid simulations, see MR 325.
- Algorithms: gemm, symm, potrf, potrs, potri, posv, getrf_nopiv, getrs_nopiv, geqrf, geqrf_hqr, gels, gels_hqr, simple and double precisions for the different sirocco machines (k40m, p100, v100, a100, rtx8000)
- Release 1.1.0 available, see changes, download source tarball.
- Chameleon has been successfully integrated into the C++ Randomized SVD library FMR.
3. Download
Depending on how much you need to tune the library installation we propose several solutions.
- You just want to have a try, to see if it can be installed well on your system, what are the performances on simple cases, run the examples, or simply use the last stable version: we recommend to use one of our packages, Guix or Spack on Linux systems, Brew on macOS.
- You want to use it but you need a change somewhere in the stack like considering another version (git branch), change the default BLAS/LAPACK or MPI, use your favorite compiler, modify some sources: you may try with Guix or Spack because these package managers allow to build from sources and thus many options can be changed dynamically (command line), or directly build from source with CMake following the procedures described in the installation guide of the library, cf. 4.
- You need a tool for reproducibility of your experiments: Guix is recommended.
| Git | Release source | Brew (Mac) | Guix (Linux) | Spack (Linux/Mac) |
|---|---|---|---|---|
| Chameleon | v1.3.0 | brew-repo | guix-repo | spack-repo |
Some packages are part of the official distribution and we just provide the package name. For others we provide links where you can find either a file to install or a package recipe that can be used with Brew, Guix, Spack. If there are no package available for your distribution please contact us and we will try to find a solution.
All these packages have been successfully installed and tested on Unix systems: Linux (Debian testing, Ubuntu 22.04 and 24.04 LTS) and macOS (Catalina).
4. Quick start guide
Here a quick starting guide for using Chameleon. For more information please refer to the full documentation.
4.1. Install
In the following we present quick examples of installation of the packages.
4.1.1. Release source installation with CMake
- Linux Ubuntu
Start by installing common development tools
sudo apt-get update -y sudo apt-get install -y git cmake build-essential gfortran python-is-python3 wget tar curl pkg-config
- CBLAS/LAPACKE is required (OpenBLAS, Intel MKL, BLIS/FLAME, IBM ESSL + Reference LAPACK for cblas/lapacke interface)
- we recommend to install StarPU as runtime system with MPI enabled and optionally CUDA/cuBLAS if enabled on your system
sudo apt-get install -y libopenblas-dev liblapacke-dev libhwloc-dev libopenmpi-dev libstarpu-dev
Remarks:
- The pair
libopenblas-dev liblapacke-devcan be replaced bylibmkl-dev. - One can also use lib blis and flame but be sure to install a cblas and lapacke, from the Reference LAPACK (with CBLAS=ON, LAPACKE=ON), linked to blis/flame.
- The lib essl (IBM) can also be used as BLAS/LAPACK with the Reference LAPACK providing cblas/lapacke.
Then to install Chameleon from sources with CMake, proceed as follows
wget https://gitlab.inria.fr/api/v4/projects/616/packages/generic/source/v1.3.0/chameleon-1.3.0.tar.gz tar xvf chameleon-1.3.0.tar.gz cd chameleon-1.3.0 # or clone the master branch from the git repository to get the last version # git clone --recursive https://gitlab.inria.fr/solverstack/chameleon.git && cd chameleon cmake -B build -DCHAMELEON_USE_MPI=ON -DBUILD_SHARED_LIBS=ON -DCMAKE_INSTALL_PREFIX=$PWD/install cmake --build build/ -j5 cmake --install build/
See more examples in the user's guide.
- macOS
Start by installing common development tools
# install Homebrew if not already available /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" # install compiler and tools brew install htop tmux gcc llvm automake autoconf libtool doxygen emacs zlib bzip2 bison hwloc pkgconfig openblas openmpi # gcc and g++ are missing (avoid to use clang version in /usr/bin or use the clang from brew, see package llvm, e.g. clang-17) ln -sf /usr/local/bin/gcc-11 /usr/local/bin/gcc ln -sf /usr/local/bin/g++-11 /usr/local/bin/g++ # use pkg-config .pc files to detect some dependencies export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:/usr/local/opt/openblas/lib/pkgconfig # cmake checks blas.pc not openblas.pc sudo cp /usr/local/opt/openblas/lib/pkgconfig/openblas.pc /usr/local/opt/openblas/lib/pkgconfig/blas.pc
- CBLAS/LAPACKE is required (OpenBLAS or Intel MKL or Reference Lapack)
- we recommend to install StarPU as runtime system with MPI enabled
# install last starpu release cd $HOME wget https://files.inria.fr/starpu/starpu-1.4.7/starpu-1.4.7.tar.gz tar xvf starpu-1.4.7.tar.gz cd starpu-1.4.7 ./configure make -j5 sudo make install
Then to install Chameleon from sources with CMake, proceed as follows
wget https://gitlab.inria.fr/api/v4/projects/616/packages/generic/source/v1.3.0/chameleon-1.3.0.tar.gz tar xvf chameleon-1.3.0.tar.gz cd chameleon-1.3.0 # or clone from git repository # git clone --recursive https://gitlab.inria.fr/solverstack/chameleon.git && cd chameleon cmake -B build -DCHAMELEON_USE_MPI=ON -DBLA_PREFER_PKGCONFIG=ON -DBUILD_SHARED_LIBS=ON cmake --build build -j5 sudo cmake --install build
4.1.2. Brew packages
Brew packages for macOS are stored in our brew-repo git repository. Please refer to the README for installation instructions.
Examples:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
git clone https://gitlab.inria.fr/solverstack/brew-repo.git
brew install --build-from-source ./brew-repo/starpu.rb
brew install --build-from-source ./brew-repo/chameleon.rb
4.1.3. Guix packages
Guix requires a running GNU/Linux system, GNU tar and Xz. Follow the installation instructions
cd /tmp
wget https://git.savannah.gnu.org/cgit/guix.git/plain/etc/guix-install.sh
chmod +x guix-install.sh
sudo ./guix-install.sh
Guix packages are stored in our guix-hpc, and guix-hpc-non-free (for versions with Intel MKL and/or CUDA) git repositories. Please refer to the README to see how to add our package to the list of Guix available packages (i.e. add a channel).
The package definitions in this repo extend those that come with
Guix. To make them visible to the guix command-line tools, create
the ~/.config/guix/channels.scm file with the following snippet to
request the guix-hpc channel:
(cons (channel
(name 'guix-hpc-non-free)
(url "https://gitlab.inria.fr/guix-hpc/guix-hpc-non-free.git"))
%default-channels)
That way, guix pull will systematically pull not only Guix, but
also Guix-HPC-non-free and Guix-HPC.
guix pull
Then to install Chameleon last release
guix install chameleon
See more examples in the user's guide.
4.1.4. Spack packages
We provide a Chameleon Spack package (with StarPU) for Linux or macOS. Please refer to the documentation for installation instructions.
Examples:
# please read https://spack.readthedocs.io/en/latest/getting_started.html git clone -c feature.manyFiles=true --depth=2 https://github.com/spack/spack.git . spack/share/spack/setup-env.sh spack install chameleon # chameleon is installed here: spack location -i chameleon
Spack allows to expose many build variants so that it is difficult to ensure that all installations will succeed.
See more examples in the user's guide.
4.2. Linking
If you do not use CMake we provide a pkg-config file at
installation in the subdirectory lib/pkgconfig.
# lets CHAMELEON_ROOT be the installation path export PKG_CONFIG_PATH=$CHAMELEON_ROOT/lib/pkgconfig:$PKG_CONFIG_PATH pkg-config --cflags chameleon pkg-config --libs chameleon pkg-config --libs --static chameleon export LD_LIBRARY_PATH=$CHAMELEON_ROOT/lib:$LD_LIBRARY_PATH
If you build your project with CMake we provide a
CHAMELEONConfig.cmake file at installation, in the subdirectory
lib/cmake/ of the installation. Configure your CMake project using
the CMAKE_PREFIX_PATH
(https://cmake.org/cmake/help/latest/envvar/CMAKE_PREFIX_PATH.html)
as environment variable or CMake variable to give the root
installation directory where Chameleon is installed.
Example of CMakeLists.txt for project using Chameleon
project(CHAMELEON_EXAMPLE C Fortran) # look for CHAMELEON on the system # Hint if not installed in a standard system directory: # add chameleon installation directory in the CMAKE_PREFIX_PATH (env. var. or cmake var.) find_package(CHAMELEON REQUIRED) # compile your example add_executable(chameleon_example chameleon_example.c) # link to chameleon target_link_libraries(chameleon_example PRIVATE CHAMELEON::chameleon)
4.3. Using
Considering that the bin/ directory of the Chameleon installation
is in the PATH, the testing executables can be used to check main
linear algebra operations such as 'gemm', 'potrf', 'getrf',
'geqrf', 'gels', etc
chameleon_stesting -H -o gemm -t 2 -m 2000 -n 2000 -k 2000
See the options with
chameleon_stesting -h
See the available linear algebra operations with
chameleon_stesting -o help
Remarks:
- If using OpenBLAS multithreaded ensure to set
OPENBLAS_NUM_THREADS=1because Chameleon handles mutithreading directly - same for Intel MKL, ensure to set
MKL_NUM_THREADS=1
Here an example of linear system solving written in C through a Cholesky factorization on a SPD matrix with LAPACK format
#include <chameleon.h> #include <stdlib.h> int main(void) { size_t N; // matrix order size_t NRHS; // number of RHS vectors int NCPU; // number of cores to use int NGPU; // number of gpus (cuda devices) to use int UPLO = ChamUpper; // where is stored L int major, minor, patch; CHAMELEON_Version(&major, &minor, &patch); /* Linear system parameters */ N = 1000; NRHS = 10; /* Initialize the number of CPUs to be used with threads */ NCPU = 2; NGPU = 0; /* Initialize CHAMELEON with main parameters */ CHAMELEON_Init( NCPU, NGPU ); /* * allocate memory for our data * - matrix A : size N x N * - set of RHS vectors B : size N x NRHS * - set of solutions vectors X : size N x NRHS */ double *A = malloc( sizeof(double) * N * N ); double *B = malloc( sizeof(double) * N * NRHS ); double *X = malloc( sizeof(double) * N * NRHS ); /* generate A matrix with random values such that it is spd */ CHAMELEON_dplgsy( (double)N, ChamUpperLower, N, A, N, 51 ); /* generate RHS */ CHAMELEON_dplrnt( N, NRHS, B, N, 5673 ); /* copy B in X before solving */ memcpy( X, B, sizeof(double) * N * NRHS ); /************************************************************/ /* solve the system AX = B using the Cholesky factorization */ /************************************************************/ /* Cholesky facorization: * A is replaced by its factorization L or L^T depending on uplo */ CHAMELEON_dpotrf( UPLO, N, A, N ); /* Solve: * B is stored in X on entry, X contains the result on exit. * Forward and back substitutions */ CHAMELEON_dpotrs(UPLO, N, NRHS, A, N, X, N); /* deallocate data */ free(A); free(B); free(X); /* Finalize CHAMELEON */ CHAMELEON_Finalize(); return EXIT_SUCCESS; }
In this example the LAPACK matrix is internally converted into Chameleon tiled matrix format then task-based algorithms can be called. The copy operation can be costly. Please consider learning how to work directly with the Chameleon tiled matrix format to get faster executions and the ability to handle distributed matrices over several machines. The user's data can be given in several way to fill the Chameleon tiled matrix, see 5.6.2.
Here a simple example of linear system solving written in C through a Cholesky factorization on a SPD matrix with Chameleon format
#include <chameleon.h> #include <stdlib.h> int main(void) { size_t N; // matrix order size_t NRHS; // number of RHS vectors int NCPU; // number of cores to use int NGPU; // number of gpus (cuda devices) to use int UPLO = ChamUpper; // where is stored L /* descriptors necessary for calling CHAMELEON tile interface */ CHAM_desc_t *descA = NULL, *descB = NULL, *descX = NULL; int major, minor, patch; CHAMELEON_Version(&major, &minor, &patch); /* Linear system parameters */ N = 1000; NRHS = 10; /* Initialize the number of CPUs to be used with threads */ NCPU = 2; NGPU = 0; /* Initialize CHAMELEON with main parameters */ CHAMELEON_Init( NCPU, NGPU ); /* * Initialize the structure required for CHAMELEON tile interface * CHAM_desc_t is a structure wrapping your data allowing CHAMELEON to get * pointers to tiles. A tile is a data subset of your matrix on which we * apply some optimized CPU/GPU kernels. * Notice that this routine suppose your matrix is a contiguous vector of * data (1D array), as a data you would give to BLAS/LAPACK. * Main arguments: * - descA is a pointer to a descriptor, you need to give the address * of this pointer * - if you want to give your allocated matrix give its address, * if not give a NULL pointer, the routine will allocate the memory * and you access the matrix data with descA->mat * - give the data type (ChamByte, ChamInteger, ChamRealFloat, * ChamRealDouble, ChamComplexFloat, ChamComplexDouble) * - number of rows in a block (tile) * - number of columns in a block (tile) * - number of elements in a block (tile) * The other parameters are specific, use: * CHAMELEON_Desc_Create( ... , 0, 0, number of rows, number of columns, 1, 1); * Have a look to the documentation for details about these parameters. */ CHAMELEON_Desc_Create(&descA, NULL, ChamRealDouble, NB, NB, NB*NB, N, N, 0, 0, N, N, 1, 1); CHAMELEON_Desc_Create(&descB, NULL, ChamRealDouble, NB, NB, NB*NB, N, NRHS, 0, 0, N, NRHS, 1, 1); CHAMELEON_Desc_Create(&descX, NULL, ChamRealDouble, NB, NB, NB*NB, N, NRHS, 0, 0, N, NRHS, 1, 1); /* generate A matrix with random values such that it is spd */ CHAMELEON_dplgsy_Tile( (double)N, ChamUpperLower, descA, 51 ); /* generate RHS */ CHAMELEON_dplrnt_Tile( descB, 5673 ); /* copy B in X before solving */ CHAMELEON_dlacpy_Tile(ChamUpperLower, descB, descX); /************************************************************/ /* solve the system AX = B using the Cholesky factorization */ /************************************************************/ /* Cholesky facorization: * A is replaced by its factorization L or L^T depending on uplo */ CHAMELEON_dpotrf_Tile( UPLO, descA ); /* Solve: * B is stored in X on entry, X contains the result on exit. * Forward and back substitutions */ CHAMELEON_dpotrs_Tile( UPLO, descA, descX ); /* deallocate data */ CHAMELEON_Desc_Destroy( &descA ); CHAMELEON_Desc_Destroy( &descB ); CHAMELEON_Desc_Destroy( &descX ); /* Finalize CHAMELEON */ CHAMELEON_Finalize(); return EXIT_SUCCESS; }
5. Documentation
This is the users guide to Chameleon. The software ecosystem will be presented, the installation instructions detailed and some usage examples are presented. To get more information about the application programming interface, please refer to the doxygen documentation.
5.1. Version
This manual documents the usage of Chameleon version 1.3.0. It was last updated on 2025-04-25.
5.3. Copying
- Copyright © 2025 Inria
- Copyright © 2014 The University of Tennessee
- Copyright © 2014 King Abdullah University of Science and Technology
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer listed in this license in the documentation and/or other materials provided with the distribution.
- Neither the name of the copyright holders nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
This software is provided by the copyright holders and contributors "as is" and any express or implied warranties, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose are disclaimed. In no event shall the copyright owner or contributors be liable for any direct, indirect, incidental, special, exemplary, or consequential damages (including, but not limited to, procurement of substitute goods or services; loss of use, data, or profits; or business interruption) however caused and on any theory of liability, whether in contract, strict liability, or tort (including negligence or otherwise) arising in any way out of the use of this software, even if advised of the possibility of such damage.
5.4. Introduction to Chameleon
5.4.1. MORSE project

Chameleon is a linear algebra software created jointly by several research teams as part of the MORSE associate team: ICL, Inria, KAUST, The University of Colorado Denver.
- MORSE Objectives
When processor clock speeds flatlined in 2004, after more than fifteen years of exponential increases, the era of near automatic performance improvements that the HPC application community had previously enjoyed came to an abrupt end. To develop software that will perform well on petascale and exascale systems with thousands of nodes and millions of cores, the list of major challenges that must now be confronted is formidable:
- dramatic escalation in the costs of intrasystem communication between processors and/or levels of memory hierarchy;
- increased heterogeneity of the processing units (mixing CPUs, GPUs, etc. in varying and unexpected design combinations);
- high levels of parallelism and more complex constraints means that cooperating processes must be dynamically and unpredictably scheduled for asynchronous execution;
- software will not run at scale without much better resilience to faults and far more robustness; and
- new levels of self-adaptivity will be required to enable software to modulate process speed in order to satisfy limited energy budgets.
The MORSE associate team will tackle the first three challenges in a orchestrating work between research groups respectively specialized in sparse linear algebra, dense linear algebra and runtime systems. The overall objective is to develop robust linear algebra libraries relying on innovative runtime systems that can fully benefit from the potential of those future large-scale complex machines. Challenges 4) and 5) will also be investigated by the different teams in the context of other partnerships, but they will not be the main focus of the associate team as they are much more prospective.
- Research fields
The overall goal of the MORSE associate team is to enable advanced numerical algorithms to be executed on a scalable unified runtime system for exploiting the full potential of future exascale machines. We expect advances in three directions based first on strong and closed interactions between the runtime and numerical linear algebra communities. This initial activity will then naturally expand to more focused but still joint research in both fields.
- Fine interaction between linear algebra and runtime systems
On parallel machines, HPC applications need to take care of data movement and consistency, which can be either explicitly managed at the level of the application itself or delegated to a runtime system. We adopt the latter approach in order to better keep up with hardware trends whose complexity is growing exponentially. One major task in this project is to define a proper interface between HPC applications and runtime systems in order to maximize productivity and expressivity. As mentioned in the next section, a widely used approach consists in abstracting the application as a DAG that the runtime system is in charge of scheduling. Scheduling such a DAG over a set of heterogeneous processing units introduces a lot of new challenges, such as predicting accurately the execution time of each type of task over each kind of unit, minimizing data transfers between memory banks, performing data prefetching, etc. Expected advances: In a nutshell, a new runtime system API will be designed to allow applications to provide scheduling hints to the runtime system and to get real-time feedback about the consequences of scheduling decisions.
- Runtime systems
A runtime environment is an intermediate layer between the system and the application. It provides low-level functionality not provided by the system (such as scheduling or management of the heterogeneity) and high-level features (such as performance portability). In the framework of this proposal, we will work on the scalability of runtime environment. To achieve scalability it is required to avoid all centralization. Here, the main problem is the scheduling of the tasks. In many task-based runtime environments the scheduler is centralized and becomes a bottleneck as soon as too many cores are involved. It is therefore required to distribute the scheduling decision or to compute a data distribution that impose the mapping of task using, for instance the so-called ``owner-compute'' rule. Expected advances: We will design runtime systems that enable an efficient and scalable use of thousands of distributed multicore nodes enhanced with accelerators.
- Linear algebra
Because of its central position in HPC and of the well understood structure of its algorithms, dense linear algebra has often pioneered new challenges that HPC had to face. Again, dense linear algebra has been in the vanguard of the new era of petascale computing with the design of new algorithms that can efficiently run on a multicore node with GPU accelerators. These algorithms are called ``communication-avoiding'' since they have been redesigned to limit the amount of communication between processing units (and between the different levels of memory hierarchy). They are expressed through Direct Acyclic Graphs (DAG) of fine-grained tasks that are dynamically scheduled. Expected advances: First, we plan to investigate the impact of these principles in the case of sparse applications (whose algorithms are slightly more complicated but often rely on dense kernels). Furthermore, both in the dense and sparse cases, the scalability on thousands of nodes is still limited; new numerical approaches need to be found. We will specifically design sparse hybrid direct/iterative methods that represent a promising approach.
- Fine interaction between linear algebra and runtime systems
- Research papers
Research papers about MORSE can be found here.
5.4.2. Chameleon
- Chameleon software
The main purpose is to address the performance shortcomings of the LAPACK and ScaLAPACK libraries on multicore processors and multi-socket systems of multicore processors and their inability to efficiently utilize accelerators such as Graphics Processing Units (GPUs).
Chameleon is a framework written in C which provides routines to solve dense general systems of linear equations, symmetric positive definite systems of linear equations and linear least squares problems, using LU, Cholesky, QR and LQ factorizations. Real arithmetic and complex arithmetic are supported in both single precision and double precision. It supports Linux and Mac OS/X machines (mainly tested on Intel x86-64 and IBM Power architectures).
Chameleon is based on the PLASMA source code but is not limited to shared-memory environment and can exploit multiple GPUs. Chameleon is interfaced in a generic way with StarPU, PaRSEC, OpenMP, QUARK runtime systems. This feature allows to analyze in a unified framework how sequential task-based algorithms behave regarding different runtime systems implementations. Using Chameleon with StarPU runtime system allows to exploit GPUs through kernels provided by cuBLAS and clusters of interconnected nodes with distributed memory (using MPI). Computation of very large systems with dense matrices on a cluster of nodes is still being experimented and stabilized. It is not expected to get stable performances with the current version using MPI.
- PLASMA's design principles
Chameleon is originally based on PLASMA so that design principles are very similar. The content of this section PLASMA's design principles has been copied from the Design principles section of the PLASMA User's Guide.
- Tile Algorithms
Tile algorithms are based on the idea of processing the matrix by square tiles of relatively small size, such that a tile fits entirely in one of the cache levels associated with one core. This way a tile can be loaded to the cache and processed completely before being evicted back to the main memory. Of the three types of cache misses, compulsory, capacity and conflict, the use of tile algorithms minimizes the number of capacity misses, since each operation loads the amount of data that does not ``overflow'' the cache.
For some operations such as matrix multiplication and Cholesky factorization, translating the classic algorithm to the tile algorithm is trivial. In the case of matrix multiplication, the tile algorithm is simply a product of applying the technique of loop tiling to the canonical definition of three nested loops. It is very similar for the Cholesky factorization. The left-looking definition of Cholesky factorization from LAPACK is a loop with a sequence of calls to four routines: xSYRK (symmetric rank-k update), xPOTRF (Cholesky factorization of a small block on the diagonal), xGEMM (matrix multiplication) and xTRSM (triangular solve). If the xSYRK, xGEMM and xTRSM operations are expressed with the canonical definition of three nested loops and the technique of loop tiling is applied, the tile algorithm results. Since the algorithm is produced by simple reordering of operations, neither the number of operations nor numerical stability of the algorithm are affected.
The situation becomes slightly more complicated for LU and QR factorizations, where the classic algorithms factorize an entire panel of the matrix (a block of columns) at every step of the algorithm. One can observe, however, that the process of matrix factorization is synonymous with introducing zeros in approproate places and a tile algorithm can be fought of as one that zeroes one tile of the matrix at a time. This process is referred to as updating of a factorization or incremental factorization. The process is equivalent to factorizing the top tile of a panel, then placing the upper triangle of the result on top of the tile blow and factorizing again, then moving to the next tile and so on. Here, the tile LU and QR algorithms perform slightly more floating point operations and require slightly more memory for auxiliary data. Also, the tile LU factorization applies a different pivoting pattern and, as a result, is less numerically stable than classic LU with full pivoting. Numerical stability is not an issue in case of the tile QR, which relies on orthogonal transformations (Householder reflections), which are numerically stable.
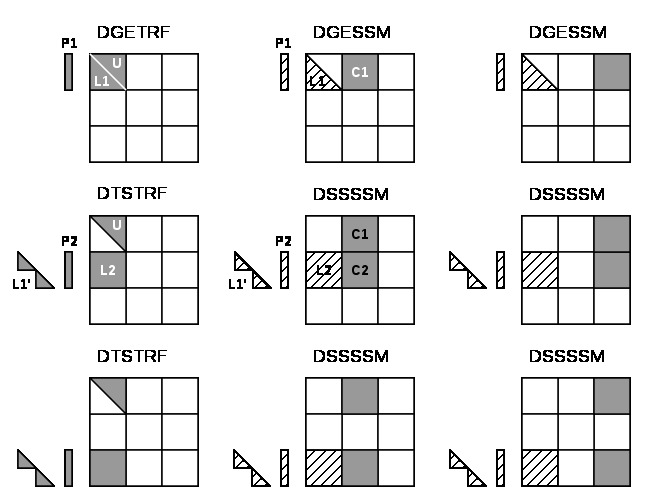
Figure 1: Schematic illustration of the tile LU factorization (kernel names for real arithmetics in double precision), courtesey of the PLASMA team.
- Tile Data Layout
Tile layout is based on the idea of storing the matrix by square tiles of relatively small size, such that each tile occupies a continuous memory region. This way a tile can be loaded to the cache memory efficiently and the risk of evicting it from the cache memory before it is completely processed is minimized. Of the three types of cache misses, compulsory, capacity and conflict, the use of tile layout minimizes the number of conflict misses, since a continuous region of memory will completely fill out a set-associative cache memory before an eviction can happen. Also, from the standpoint of multithreaded execution, the probability of false sharing is minimized. It can only affect the cache lines containing the beginning and the ending of a tile.
In standard cache-based architecture, tiles continously laid out in memory maximize the profit from automatic prefetching. Tile layout is also beneficial in situations involving the use of accelerators, where explicit communication of tiles through DMA transfers is required, such as moving tiles between the system memory and the local store in Cell B. E. or moving tiles between the host memory and the device memory in GPUs. In most circumstances tile layout also minimizes the number of TLB misses and conflicts to memory banks or partitions. With the standard (column-major) layout, access to each column of a tile is much more likely to cause a conflict miss, a false sharing miss, a TLB miss or a bank or partition conflict. The use of the standard layout for dense matrix operations is a performance minefield. Although occasionally one can pass through it unscathed, the risk of hitting a spot deadly to performance is very high.
Another property of the layout utilized in PLASMA is that it is ``flat'', meaning that it does not involve a level of indirection. Each tile stores a small square submatrix of the main matrix in a column-major layout. In turn, the main matrix is an arrangement of tiles immediately following one another in a column-major layout. The offset of each tile can be calculated through address arithmetics and does not involve pointer indirection. Alternatively, a matrix could be represented as an array of pointers to tiles, located anywhere in memory. Such layout would be a radical and unjustifiable departure from LAPACK and ScaLAPACK. Flat tile layout is a natural progression from LAPACK's column-major layout and ScaLAPACK's block-cyclic layout.
Another related property of PLASMA's tile layout is that it includes provisions for padding of tiles, i.e., the actual region of memory designated for a tile can be larger than the memory occupied by the actual data. This allows to force a certain alignment of tile boundaries, while using the flat organization described in the previous paragraph. The motivation is that, at the price of small memory overhead, alignment of tile boundaries may prove benefivial in multiple scenarios involving memory systems of standard multicore processors, as well as accelerators. The issues that come into play are, again, the use of TLBs and memory banks or partitions.
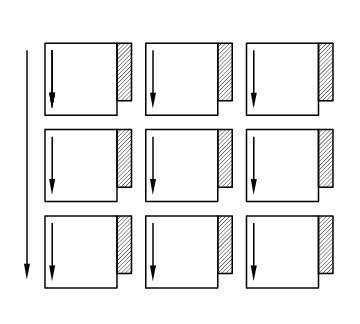
Figure 2: Schematic illustration of the tile layout with column-major order of tiles, column-major order of elements within tiles and (optional) padding for enforcing a certain alighment of tile bondaries, courtesey of the PLASMA team.
- Dynamic Task Scheduling
Dynamic scheduling is the idea of assigning work to cores based on the availability of data for processing at any given point in time and is also referred to as data-driven scheduling. The concept is related closely to the idea of expressing computation through a task graph, often referred to as the DAG (Direct Acyclic Graph), and the flexibility exploring the DAG at runtime. Thus, to a large extent, dynamic scheduling is synonymous with runtime scheduling. An important concept here is the one of the critical path, which defines the upper bound on the achievable parallelism, and needs to be pursued at the maximum speed. This is in direct opposition to the fork-and-join or data-parallel programming models, where artificial synchronization points expose serial sections of the code, where multiple cores are idle, while sequential processing takes place. The use of dynamic scheduling introduces a trade-off, though. The more dynamic (flexible) scheduling is, the more centralized (and less scalable) the scheduling mechanism is. For that reason, currently PLASMA uses two scheduling mechanisms, one which is fully dynamic and one where work is assigned statically and dependency checks are done at runtime.
The first scheduling mechanism relies on unfolding a sliding window of the task graph at runtime and scheduling work by resolving data hazards: Read After Write(RAW), Write After Read (WAR) and Write After Write (WAW), a technique analogous to instruction scheduling in superscalar processors. It also relies on work-stealing for balanding the load among all multiple cores. The second scheduling mechanism relies on statically designating a path through the execution space of the algorithm to each core and following a cycle: transition to a task, wait for its dependencies, execute it, update the overall progress. Task are identified by tuples and task transitions are done through locally evaluated formulas. Progress information can be centralized, replicated or distributed (currently centralized).
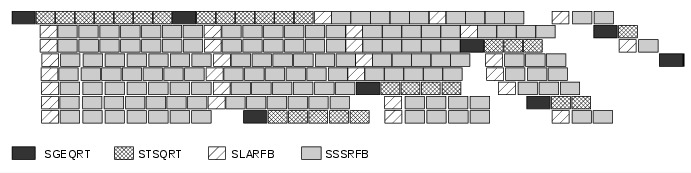
Figure 3: A trace of the tile QR factorization executing on eight cores without any global synchronization points (kernel names for real arithmetics in single precision), courtesey of the PLASMA team.
- Tile Algorithms
5.5. Installing Chameleon
Chameleon is written in C and depends on a couple of external libraries that must be installed on the system.
Chameleon can be built and installed on UNIX systems (Linux) by the standard means of CMake. General information about CMake, as well as installation binaries and CMake source code are available from here.
To get support to install a full distribution Chameleon + dependencies we encourage users to use GNU Guix or Spack and Brew on macOS.
5.5.1. Getting Chameleon
The latest official release tarballs of Chameleon sources are available for download from the gitlab tags page.
The latest development state is available on gitlab. You need Git
git clone --recursive https://gitlab.inria.fr/solverstack/chameleon.git
5.5.2. Prerequisites for installing Chameleon
To install Chameleon's libraries, header files, and executables, one needs:
- CMake (version 3.3 minimum, 3.17 to compile with the H-Mat support): the build system
- C and Fortran compilers: GNU compiler suite, Clang, Intel or IBM can be used
- python: to generate files in the different precisions
- external libraries: this depends on the configuration, by default the required libraries are
Optional libraries:
These packages must be installed on the system before trying to configure/build chameleon. Please look at the distrib/ directory which gives some hints for the installation of dependencies for Unix systems.
We give here some examples for a Debian system:
# Update Debian packages list sudo apt-get update # Install BLAS/LAPACK, can be OpenBLAS, Intel MKL, Netlib LAPACK sudo apt-get install -y libopenblas-dev liblapacke-dev # or sudo apt-get install -y libmkl-dev # or sudo apt-get install -y liblapack-dev liblapacke-dev # Install OpenMPI sudo apt-get install -y libopenmpi-dev # Install StarPU sudo apt-get install libstarpu-dev # Optionnaly to make some specific developments, the following may be installed # Install hwloc (used by StarPU or QUARK, already a dependency of OpenMPI) sudo apt-get install -y libhwloc-dev # install EZTrace, usefull to export some nice execution traces with all runtimes sudo apt-get install -y libeztrace-dev # install FxT, usefull to export some nice execution traces with StarPU sudo apt-get install -y libfxt-dev # Install cuda and cuBLAS: only if you have a GPU cuda compatible sudo apt-get install -y nvidia-cuda-toolkit nvidia-cuda-dev # Install HIP and hipBLAS: only if you have a GPU AMD compatible curl -fsSL https://repo.radeon.com/rocm/rocm.gpg.key | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/rocm-keyring.gpg echo 'deb [arch=amd64 signed-by=/etc/apt/trusted.gpg.d/rocm-keyring.gpg] https://repo.radeon.com/rocm/apt/5.4.2 jammy main' | sudo tee /etc/apt/sources.list.d/rocm.list echo -e 'Package: *\nPin: release o=repo.radeon.com\nPin-Priority: 600' | sudo tee /etc/apt/preferences.d/rocm-pin-600 sudo apt-get update sudo apt-get install -y rocm-hip-sdk # If you prefer a specific version of StarPU, install it yourself, e.g. # Install StarPU (with MPI and FxT enabled) mkdir -p $HOME/install cd $HOME/install wget https://files.inria.fr/starpu/starpu-1.4.7/starpu-1.4.7.tar.gz tar xvf starpu-1.4.7.tar.gz cd starpu-1.4.7 ./configure --prefix=/usr/local --with-fxt=/usr/lib/x86_64-linux-gnu/ make -j5 sudo make install # Install PaRSEC: to be used in place of StarPU mkdir -p $HOME/install cd $HOME/install git clone https://bitbucket.org/mfaverge/parsec.git cd parsec git checkout mymaster git submodule update mkdir -p build cd build cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local -DBUILD_SHARED_LIBS=ON make -j5 sudo make install # Install QUARK: to be used in place of StarPU mkdir -p $HOME/install cd $HOME/install git clone https://github.com/ecrc/quark cd quark/ sed -i -e "s#prefix=.*#prefix=/usr/local#g" make.inc sed -i -e "s#CFLAGS=.*#CFLAGS= -O2 -DADD_ -fPIC#g" make.inc make sudo make install
See also our script example in the distrib/debian sub-directory.
- Known issues
- we need the lapacke interface to tmg routines and symbol like
LAPACKE_dlatms_workshould be defined in the lapacke library. Make sure the Debian packages libopenblas-dev and liblapacke-dev (no problem with Intel MKL) do provide the tmg interface. If not you can possibly update your distribution or install the lapacke interface library in another way, by yourself from source or with Spack, or with Guix-HPC,…
- we need the lapacke interface to tmg routines and symbol like
- Some details about dependencies
- BLAS implementation
BLAS (Basic Linear Algebra Subprograms), are a de facto standard for basic linear algebra operations such as vector and matrix multiplication. FORTRAN implementation of BLAS is available from Netlib. Also, C implementation of BLAS is included in GSL (GNU Scientific Library). Both these implementations are reference implementation of BLAS, are not optimized for modern processor architectures and provide an order of magnitude lower performance than optimized implementations. Highly optimized implementations of BLAS are available from many hardware vendors, such as Intel MKL, IBM ESSL and AMD ACML. Fast implementations are also available as academic packages, such as ATLAS and OpenBLAS. The standard interface to BLAS is the FORTRAN interface.
Caution about the compatibility: Chameleon has been mainly tested with the reference BLAS from NETLIB, OpenBLAS and Intel MKL.
- CBLAS
CBLAS is a C language interface to BLAS. Most commercial and academic implementations of BLAS also provide CBLAS. Netlib provides a reference implementation of CBLAS on top of FORTRAN BLAS (Netlib CBLAS). Since GSL is implemented in C, it naturally provides CBLAS.
Caution about the compatibility: Chameleon has been mainly tested with the reference CBLAS from NETLIB, OpenBLAS and Intel MKL.
- LAPACK implementation
LAPACK (Linear Algebra PACKage) is a software library for numerical linear algebra, a successor of LINPACK and EISPACK and a predecessor of Chameleon. LAPACK provides routines for solving linear systems of equations, linear least square problems, eigenvalue problems and singular value problems. Most commercial and academic BLAS packages also provide some LAPACK routines.
Caution about the compatibility: Chameleon has been mainly tested with the reference LAPACK from NETLIB, OpenBLAS and Intel MKL.
- LAPACKE
LAPACKE is a C language interface to LAPACK (or CLAPACK). It is produced by Intel in coordination with the LAPACK team and is available in source code from Netlib in its original version (Netlib LAPACKE) and from Chameleon website in an extended version (LAPACKE for Chameleon). In addition to implementing the C interface, LAPACKE also provides routines which automatically handle workspace allocation, making the use of LAPACK much more convenient.
Caution about the compatibility: Chameleon has been mainly tested with the reference LAPACKE from NETLIB, OpenBLAS and Intel MKL. In addition the LAPACKE library must be configured to provide the interface with the TMG routines and symbols like
LAPACKE_dlatms_workshould be defined. - libtmg
libtmg is a component of the LAPACK library, containing routines for generation of input matrices for testing and timing of LAPACK. The testing and timing suites of LAPACK require libtmg, but not the library itself. Note that the LAPACK library can be built and used without libtmg.
Caution about the compatibility: Chameleon has been mainly tested with the reference TMGLIB from NETLIB, OpenBLAS and Intel MKL.
- StarPU
StarPU is a task programming library for hybrid architectures. StarPU handles run-time concerns such as:
- Task dependencies
- Optimized heterogeneous scheduling
- Optimized data transfers and replication between main memory and discrete memories
- Optimized cluster communications
StarPU can be used to benefit from GPUs and distributed-memory environment. Note StarPU is enabled by default.
Caution about the compatibility: current Chameleon has been mainly tested with StarPU-1.4 releases.
- PaRSEC
PaRSEC is a generic framework for architecture aware scheduling and management of micro-tasks on distributed many-core heterogeneous architectures.
Caution about the compatibility: Chameleon is compatible with this version https://bitbucket.org/mfaverge/parsec/branch/mymaster.
- QUARK
QUARK (QUeuing And Runtime for Kernels) provides a library that enables the dynamic execution of tasks with data dependencies in a multi-core, multi-socket, shared-memory environment. When Chameleon is linked with QUARK or OPENMP, it is not possible to exploit neither CUDA (for GPUs) nor MPI (distributed-memory environment). You can use StarPU to do so.
Caution about the compatibility: Chameleon has been mainly tested with the QUARK library coming from https://github.com/ecrc/quark.
- EZTrace
This library provides efficient modules for recording traces. Chameleon can trace kernels execution on CPU workers thanks to EZTrace and produce .paje files. EZTrace also provides integrated modules to trace MPI calls and/or memory usage. See how to use this feature here Execution trace using EZTrace. To trace kernels execution on all kind of workers, such as CUDA, We recommend to use the internal tracing support of the runtime system used done by the underlying runtime. See how to use this feature here Execution trace using StarPU/FxT.
- hwloc
hwloc (Portable Hardware Locality) is a software package for accessing the topology of a multicore system including components like: cores, sockets, caches and NUMA nodes. The topology discovery library,
hwloc, is strongly recommended to be used through the runtime system. It allows to increase performance, and to perform some topology aware scheduling.hwlocis available in major distributions and for most OSes and can be downloaded from http://www.open-mpi.org/software/hwloc.Caution about the compatibility: hwloc should be compatible with the runtime system used.
- OpenMPI
OpenMPI is an open source Message Passing Interface implementation for execution on multiple nodes with distributed-memory environment. MPI can be enabled only if the runtime system chosen is StarPU (default). To use MPI through StarPU, it is necessary to compile StarPU with MPI enabled.
Caution about the compatibility: OpenMPI should be built with the –enable-mpi-thread-multiple option.
- Nvidia CUDA Toolkit
Nvidia CUDA Toolkit provides a comprehensive development environment for C and C++ developers building GPU-accelerated applications. Chameleon can use a set of low level optimized kernels coming from cuBLAS to accelerate computations on GPUs. The cuBLAS library is an implementation of BLAS (Basic Linear Algebra Subprograms) on top of the Nvidia CUDA runtime. cuBLAS is normaly distributed with Nvidia CUDA Toolkit. CUDA/cuBLAS can be enabled in Chameleon only if the runtime system chosen is StarPU (default). To use CUDA through StarPU, it is necessary to compile StarPU with CUDA enabled.
Caution about the compatibility: your compiler must be compatible with CUDA.
- HIP
HIP is a C++ Runtime API and Kernel Language that allows developers to create portable applications for AMD and NVIDIA GPUs from single source code.
- BLAS implementation
5.5.3. Build and install Chameleon with CMake
Compilation of Chameleon libraries and executables are done with CMake (http://www.cmake.org/). This version has been tested with CMake 3.10.2 but any version superior to 3.3 should be fine, unless you enable the H-Mat support that requires the minimum revision to be 3.17.
Here the steps to configure, build, test and install
configure:
cmake path/to/chameleon -DOPTION1= -DOPTION2= ... # see the "Configuration options" section to get list of options # see the "Dependencies detection" for details about libraries detection
build:
make # do not hesitate to use -j[ncores] option to speedup the compilation
test (optional, required CHAMELEON_ENABLE_TESTING=ON):
make test # or ctest
install (optional):
make install
Do not forget to specify the install directory with -DCMAKE_INSTALL_PREFIX at configure.
cmake /home/jdoe/chameleon -DCMAKE_INSTALL_PREFIX=/home/jdoe/install/chameleon
Note that the install process is optional. You are free to use Chameleon binaries compiled in the build directory.
- Configuration options
You can optionally activate some options at cmake configure (like CUDA, MPI, …) invoking
cmake path/to/your/CMakeLists.txt -DOPTION1= -DOPTION2= ...cmake /home/jdoe/chameleon/ -DCMAKE_BUILD_TYPE=Debug \ -DCMAKE_INSTALL_PREFIX=/home/jdoe/install/ \ -DCHAMELEON_USE_CUDA=ON \ -DCHAMELEON_USE_MPI=ON \ -DBLA_VENDOR=Intel10_64lp_seqYou can get the full list of options with -L[A][H] options of cmake command
cmake -LH /home/jdoe/chameleon/
You can also set the options thanks to the ccmake interface.
- Native CMake options (non-exhaustive list)
- CMAKE_BUILD_TYPE=Debug|Release|RelWithDebInfo|MinSizeRel: level of compiler optimization, enable/disable debug information.
- CMAKE_PREFIX_PATH="path1;path2": where paths denotes root to dependencies that may be installed with CMake.
- CMAKE_INSTALL_PREFIX=path/to/your/install/dir: where headers, libraries, executables, etc, will be copied when invoking make install.
- BUILD_SHARED_LIBS=ON|OFF:
indicates whether or not CMake has to build Chameleon static (
OFF) or shared (ON) libraries. - CMAKE_C_COMPILER=gcc|icc|…: to choose the C compilers if several exist in the environment
- CMAKE_Fortran_COMPILER=gfortran|ifort|…: to choose the Fortran compilers if several exist in the environment
- Related to specific modules (find_package) to find external libraries
- BLA_VENDOR=All|OpenBLAS|Generic|Intel10_64lp|Intel10_64lp_seq|FLAME: to use intel mkl for example, see the list of BLA_VENDOR.
Libraries detected with an official cmake module (see module files in CMAKE_ROOT/Modules/): BLAS - LAPACK - CUDA - MPI - OpenMP - Threads.
Libraries detected with our cmake modules (see module files in cmake_modules/morse_cmake/modules/find/ directory of Chameleon sources): CBLAS - EZTRACE - FXT - HWLOC - LAPACKE - PARSEC - QUARK - SIMGRID - STARPU.
- Chameleon specific options
- CHAMELEON_SCHED=STARPU|PARSEC|QUARK|OPENMP (default STARPU): to link respectively with StarPU, PaRSEC, Quark, OpenMP library (runtime system)
- CHAMELEON_USE_MPI=ON|OFF (default OFF): to link with MPI library (message passing implementation for use of multiple nodes with distributed memory), can only be used with StarPU
- CHAMELEON_USE_CUDA=ON|OFF (default OFF): to link with CUDA runtime (implementation paradigm for accelerated codes on Nvidia GPUs) and cuBLAS library (optimized BLAS kernels on Nvidia GPUs), can only be used with StarPU and PaRSEC
- CHAMELEON_USE_HIP_ROC=ON|OFF (default OFF): to link with HIP runtime (implementation paradigm for accelerated codes on AMD GPUs) and hipBLAS library (optimized BLAS kernels on AMD GPUs), can only be used with StarPU
- CHAMELEON_USE_HIP_CUDA=ON|OFF (default OFF): to link with HIP runtime (implementation paradigm for accelerated codes on Nvidia GPUs) and hipBLAS library (optimized BLAS kernels on Nvidia GPUs), can only be used with StarPU
- CHAMELEON_ENABLE_DOC=ON|OFF (default OFF): to control build of the documentation contained in doc/ sub-directory
- CHAMELEON_ENABLE_EXAMPLE=ON|OFF (default ON): to control build of the examples executables (API usage) contained in example/ sub-directory
- CHAMELEON_ENABLE_PRUNING_STATS=ON|OFF (default OFF)
- CHAMELEON_ENABLE_TESTING=ON|OFF (default ON): to control build of testing executables (timer and numerical check) contained in testing/ sub-directory
- CHAMELEON_SIMULATION=ON|OFF (default OFF): to enable simulation mode, means Chameleon will not really execute tasks, see details in section Use simulation mode with StarPU-SimGrid. This option must be used with StarPU compiled with SimGrid allowing to guess the execution time on any architecture. This feature should be used to make experiments on the scheduler behaviors and performances not to produce solutions of linear systems.
- CHAMELEON_USE_MIGRATE=ON|OFF (default OFF): enables the data migration in QR algorithms.
- CHAMELEON_USE_MPI_DATATYPES (default OFF): enables MPI datatypes whenever supported by the runtime.
- CHAMELEON_USE_HMATOSS=ON|OFF (default OFF): enables Hmat-OSS kernels.
- CHAMELEON_RUNTIME_SYNC (default OFF): enables synchronous task submission when available to debug the code without parallelism.
- CHAMELEON_KERNELS_TRACE (default OFF): enables kernel traces to debug the task execution order.
- CHAMELEON_KERNELS_MT (default OFF): Use multithreaded kernels (e.g. intel MKL MT)
- Native CMake options (non-exhaustive list)
- Dependencies detection
You have different choices to detect dependencies on your system, either by setting some environment variables containing paths to the libs and headers or by specifying them directly at cmake configure. In any case, if the dependencies are installed in non standard directories, do not forget to use the
PKG_CONFIG_PATHenvironment variable and theCMAKE_PREFIX_PATHenvironment (or CMake) variable. Different cases:- detection of dependencies through environment variables:
LD_LIBRARY_PATH (DYLD_LIBRARY_PATH on Mac OSX) should contain the list of paths where to find the libraries:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:install/path/to/your/lib
INCLUDE (or CPATH, or C_INCLUDE_PATH)should contain the list of paths where to find the header files of libraries
export INCLUDE=$INCLUDE:install/path/to/your/headers
- detection with user's given paths:
you can specify the path at cmake configure by invoking
cmake path/to/your/CMakeLists.txt -DLIB_DIR=path/to/your/lib
where LIB stands for the name of the lib to look for, e.g.
cmake path/to/your/CMakeLists.txt -DQUARK_DIR=path/to/quarkdir \ -DCBLAS_DIR= ...it is also possible to specify headers and library directories separately
cmake path/to/your/CMakeLists.txt \ -DQUARK_INCDIR=path/to/quark/include \ -DQUARK_LIBDIR=path/to/quark/lib
- detection with custom environment variables: all variables like _DIR, _INCDIR, _LIBDIR can be set as environment variables instead of CMake options, there will be read
- using pkg-config for libraries that provide .pc files
- update your PKG_CONFIG_PATH to the paths where to find .pc files of installed external libraries like hwloc, starpu, some blas/lapack, etc
- using CMAKE_PREFIX_PATH for libraries that provide some CMake config files containing targets definitions (e.g. fooConfig.cmake).
Note that PaRSEC and StarPU are only detected with pkg-config mechanism because it is always provided and this avoids errors. The CMAKE_PREFIX_PATH can be used to indicate where dependencies are installed.
- detection of dependencies through environment variables:
5.5.4. Distribution of Chameleon using GNU Guix
We provide Guix packages to install Chameleon with its dependencies in a reproducible way on GNU/Linux systems. For macOS please refer to the next sections about Brew or Spack packaging.
If you are "root" on the system you can install Guix and directly use it to install the libraries. On supercomputers your are not root on you may still be able to use it if Docker or Singularity are available on the machine because Chameleon can be packaged as Docker/Singularity images with Guix.
- Installing Guix
Guix requires a running GNU/Linux system, GNU tar and Xz. Follow the installation instructions
cd /tmp wget https://git.savannah.gnu.org/cgit/guix.git/plain/etc/guix-install.sh chmod +x guix-install.sh sudo ./guix-install.shThe Chameleon packages are not official Guix packages. It is then necessary to add a channel to get additional packages. Create a ~/.config/guix/channels.scm file with the following snippet:
(cons (channel (name 'guix-hpc-non-free) (url "https://gitlab.inria.fr/guix-hpc/guix-hpc-non-free.git")) %default-channels)Update guix package definition
guix pull
Update new guix in the path
PATH="$HOME/.config/guix/current/bin${PATH:+:}$PATH" hash guix
For further shell sessions, add this to the ~/.bash_profile file
export PATH="$HOME/.config/guix/current/bin${PATH:+:}$PATH" export GUIX_LOCPATH="$HOME/.guix-profile/lib/locale"Chameleon packages are now available
guix search ^chameleon
Refer to the official documentation of Guix to learn the basic commands.
- Installing Chameleon with Guix
Standard Chameleon, last release
guix install chameleon # or use guix shell to get a new shell (isolated from the native environment) with chameleon available in the PATH guix shell --pure chameleon -- /bin/bash --norc
Notice that there exist several build variants
- chameleon (default) : with starpu - with mpi - with OpenBlas
- chameleon-aocl : with starpu - with mpi - with FLAME/BLIS from AMD
- chameleon-mkl : default version but with Intel MKL sequential to replace OpenBlas
- chameleon-mkl-mt : default version but with Intel MKL multithreaded to replace OpenBlas
- chameleon-mkl-mt-nompi : with Intel MKL multithreaded and without mpi
- chameleon-cuda : with starpu - with cuda - with OpenBlas - with mpi
- chameleon-cuda-nompi : with starpu - with cuda - with OpenBlas - without mpi
- chameleon-cuda-mkl-mt : with starpu - with cuda - with Intel MKL multithreaded - with mpi
- chameleon-cuda-mkl-mt-nompi : with starpu - with cuda - with Intel MKL multithreaded - without mpi
- chameleon-hip : with starpu - with hip - with OpenBlas - with mpi
- chameleon-hip-nompi : with starpu - with hip - with OpenBlas - without mpi
- chameleon-hip-mkl-mt : with starpu - with hip - with Intel MKL multithreaded - with mpi
- chameleon-hip-mkl-mt-nompi : with starpu - with hip - with Intel MKL multithreaded - without mpi
- chameleon-simgrid : with starpu - with mpi - with simgrid
- chameleon-openmp : with openmp - without mpi
- chameleon-parsec : with parsec - without mpi
- chameleon-quark : with quark - without mpi
Change the version
guix install chameleon --with-branch=chameleon=master guix install chameleon --with-commit=chameleon=b31d7575fb7d9c0e1ba2d8ec633e16cb83778e8b guix install chameleon --with-git-url=chameleon=https://gitlab.inria.fr/fpruvost/chameleon.git guix install chameleon --with-source=chameleon=$HOME/git/chameleon
Notice also that default mpi is OpenMPI and default blas/lapack is Openblas. This can be changed with a transformation option.
Change some dependencies
# install chameleon with intel mkl to replace openblas, nmad to replace openmpi and starpu with fxt guix install chameleon --with-input=openblas=intel-oneapi-mkl --with-input=openmpi=nmad --with-input=starpu=starpu-fxt
- Generate a Chameleon Docker image with Guix
To install Chameleon and its dependencies within a docker image (OpenMPI stack)
docker_chameleon=`guix pack -f docker chameleon chameleon --with-branch=chameleon=master --with-input=openblas=intel-oneapi-mkl intel-oneapi-mkl starpu hwloc openmpi@4 openssh slurm bash coreutils inetutils util-linux procps git grep tar sed gzip which gawk perl emacs-minimal vim gcc-toolchain pkg-config -S /bin=bin --entry-point=/bin/bash` # Load the generated tarball as a docker image docker_chameleon_tag=`docker load --input $docker_chameleon | grep "Loaded image: " | cut -d " " -f 3-` # Change tag name, see the existing image name with "docker images" command, then change to a more simple name docker tag $docker_chameleon_tag guix/chameleon-tmp
Create a Dockerfile inheriting from the image (renamed
guix/chameleonhere):FROM guix/chameleon-tmp # Create a directory for user 1000 RUN mkdir -p /builds RUN chown -R 1000 /builds ENTRYPOINT ["/bin/bash", "-l"] # Enter the image as user 1000 in /builds USER 1000 WORKDIR /builds ENV HOME /builds
Then create the final docker image from this docker file.
docker build -t guix/chameleon .
Test the image
docker run -it guix/chameleon # test starpu STARPU=`pkg-config --variable=prefix libstarpu` mpiexec -np 4 $STARPU/lib/starpu/mpi/comm # test chameleon CHAMELEON=`pkg-config --variable=prefix chameleon` mpiexec -np 2 $CHAMELEON/bin/chameleon_stesting -H -o gemm -P 2 -t 2 -m 2000 -n 2000 -k 2000
- Generate a Chameleon Singularity image with Guix
To package Chameleon and its dependencies within a singularity image (OpenMPI stack)
# define reproducible guix environment guix describe -f channels > guix-channels.scm guix shell --export-manifest chameleon-cuda --with-branch=chameleon=master --with-input=openblas=intel-oneapi-mkl bash coreutils emacs gawk grep inetutils openmpi@4 openssh procps sed time util-linux vim which > guix-manifests.scm SINGULARITY_IMAGE=`guix time-machine -C guix-channels.scm -- pack -f squashfs -m guix-manifests.scm -S /bin=bin --entry-point=/bin/bash` cp $SINGULARITY_IMAGE chameleon-cuda.gz.sif # copy the singularity image on the supercomputer, e.g. 'supercomputer' scp chameleon-cuda.gz.sif supercomputer:
On a machine where Singularity is installed Chameleon can then be called as follows
# at least openmpi and singularity are required here, e.g. module add openmpi singularity module add openmpi singularity export SINGULARITY_CMD=`which singularity` export SINGULARITY_IMAGE=$HOME/chameleon-cuda.gz.sif # use LD_PRELOAD to give the location of the CUDA driver installed on the supercomputer export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libcuda.so # then in your allocation with Slurm or OAR, for example mpirun $MPI_OPTIONS -x LD_PRELOAD $SINGULARITY_CMD exec --bind /usr/lib/x86_64-linux-gnu/:/usr/lib/x86_64-linux-gnu/ $SINGULARITY_IMAGE chameleon_stesting -o gemm -n 96000 -b 1600 --nowarmup -g 2
- Generate a tar.gz package of Chameleon with Guix
One can generate a tar.gz archive the same way as the singularity image
guix describe -f channels > guix-channels.scm guix shell --export-manifest chameleon-cuda --with-branch=chameleon=master --with-input=openblas=intel-oneapi-mkl bash coreutils emacs gawk grep inetutils openmpi openssh procps sed time util-linux vim which > guix-manifests.scm PACKRR=`guix time-machine --channels=guix-channels.scm -- pack -RR --manifest=guix-manifests.scm -S /bin=bin` cp $PACKRR chameleon-cuda.tar.gz # copy the archive on the supercomputer, e.g. 'supercomputer' scp chameleon-cuda.tar.gz supercomputer:
Then on the supercomputer that has neither Guix nor Singularity one can do the following
mkdir guixrr/ cd guixrr/ tar xvf $HOME/chameleon-cuda.tar.gz chmod +w . export GUIX_ROOT=$PWD # then in your allocation with Slurm or OAR, for example ${GUIX_ROOT}/bin/mpirun --launch-agent ${GUIX_ROOT}/bin/orted -x GUIX_EXECUTION_ENGINE=performance -x LD_PRELOAD="/usr/lib64/libcuda.so" -x STARPU_SILENT=1 ${GUIX_ROOT}/bin/chameleon_stesting -o gemm -n 16000,32000,64000,96000,128000 -b 2000 -g 4 -P 2
5.5.5. Distribution of Chameleon using Spack
- Installing Spack
We provide a Chameleon Spack package (with StarPU) for Linux or macOS. Please refer to the documentation for installation instructions.
# please read https://spack.readthedocs.io/en/latest/getting_started.html git clone https://github.com/spack/spack.git . spack/share/spack/setup-env.sh cd spack
Chameleon is then available
spack info chameleon spack spec chameleon
Refer to the getting started guide and basic usage guide to learn how to use Spack properly.
- Installing Chameleon with Spack
Standard Chameleon, last state on the 'master' branch
spack install -v chameleon # chameleon is installed here: spack location -i chameleon
Notice that there exist several build variants (see
spack info chameleon)- chameleon (default) : with starpu - with mpi
- tune the build type (CMake) with build_type=RelWithDebInfo|Debug|Release
- enable/disable shared libraries with +/- shared
- enable/disable mpi with +/- mpi
- enable/disable cuda with +/- cuda
- enable/disable fxt with +/- fxt
- enable/disable simgrid with +/- simgrid
- runtime=openmp : with openmp - without starpu
Change the version
spack install -v chameleon@master
Notice also that default mpi is OpenMPI and default blas/lapack is Openblas. This can be changed by adding some constraints on virtual packages.
Change some dependencies
# see lapack providers spack providers lapack # see mpi providers spack providers mpi # install chameleon with intel mkl to replace openblas spack install -v chameleon ^intel-mkl # or ^intel-oneapi-mkl
5.5.6. Distribution Brew for Mac OS X
We provide some brew packages here https://gitlab.inria.fr/solverstack/brew-repo (under construction).
5.5.7. Linking an external application with Chameleon libraries
Compilation and link with Chameleon libraries have been tested with
the GNU compiler suite gcc/gfortran and the Intel compiler suite
icc/ifort.
- For CMake projects
A CHAMELEONConfig.cmake file is provided at installation, stored in <prefix>/lib/cmake/chameleon, so that users in cmake project can use through the variable CHAMELEON_ROOT (set it as environment or CMake variable).
sudo apt-get update sudo apt-get install -y libopenblas-dev liblapacke-dev libstarpu-dev git clone --recursive https://gitlab.inria.fr/solverstack/chameleon.git cd chameleon && mkdir -p build && cd build CHAMELEON_ROOT=$PWD/install cmake .. -DCMAKE_INSTALL_PREFIX=$CHAMELEON_ROOT && make -j5 install # chameleon is installed in $CHAMELEON_ROOT # if your work in a cmake project you can use the CHAMELEONConfig.cmake file # installed under <prefix>/lib/cmake/chameleon/ by setting your # CMAKE_PREFIX_PATH with the path of installation. In your cmake project, use # find_package(CHAMELEON) and link your libraries and/or executables with the # library target CHAMELEON::chameleon cmake . -DCMAKE_PREFIX_PATH=$CHAMELEON_ROOT
- For non CMake projects
The compiler, linker flags that are necessary to build an application using Chameleon are given through the pkg-config mechanism.
sudo apt-get update sudo apt-get install -y libopenblas-dev liblapacke-dev libstarpu-dev git clone --recursive https://gitlab.inria.fr/solverstack/chameleon.git cd chameleon && mkdir -p build && cd build CHAMELEON_ROOT=$PWD/install cmake .. -DCMAKE_INSTALL_PREFIX=$CHAMELEON_ROOT && make -j5 install # chameleon is installed in $CHAMELEON_ROOT export PKG_CONFIG_PATH=$CHAMELEON_ROOT/lib/pkgconfig:$PKG_CONFIG_PATH pkg-config --cflags chameleon pkg-config --libs chameleon pkg-config --libs --static chameleon # use it in your configure/make
The .pc files required are located in the sub-directory
lib/pkgconfigof your Chameleon install directory. - Static linking in C
Lets imagine you have a file
main.cthat you want to link with Chameleon static libraries. Lets consider/home/yourname/install/chameleonis the install directory of Chameleon containing sub-directoriesinclude/andlib/. Here could be your compilation command with gcc compiler:gcc -I/home/yourname/install/chameleon/include -o main.o -c main.c
Now if you want to link your application with Chameleon static libraries, you could do:
gcc main.o -o main \ /home/yourname/install/chameleon/lib/libchameleon.a \ /home/yourname/install/chameleon/lib/libchameleon_starpu.a \ /home/yourname/install/chameleon/lib/libcoreblas.a \ -lstarpu-1.3 -Wl,--no-as-needed -lmkl_intel_lp64 \ -lmkl_sequential -lmkl_core -lpthread -lm -lrt
As you can see in this example, we also link with some dynamic libraries starpu-1.3, Intel MKL libraries (for BLAS/LAPACK/CBLAS/LAPACKE), pthread, m (math) and rt. These libraries will depend on the configuration of your Chameleon build. You can find these dependencies in .pc files we generate during compilation and that are installed in the sub-directory
lib/pkgconfigof your Chameleon install directory. Note also that you could need to specify where to find these libraries with -L option of your compiler/linker.Before to run your program, make sure that all shared libraries paths your executable depends on are known. Enter
ldd mainto check. If some shared libraries paths are missing append them in the LD_LIBRARY_PATH (for Linux systems) environment variable (DYLD_LIBRARY_PATH on Mac). - Dynamic linking in C
For dynamic linking (need to build Chameleon with CMake option BUILD_SHARED_LIBS=ON) it is similar to static compilation/link but instead of specifying path to your static libraries you indicate the path to dynamic libraries with -L option and you give the name of libraries with -l option like this:
gcc main.o -o main \ -L/home/yourname/install/chameleon/lib \ -lchameleon -lchameleon_starpu -lcoreblas \ -lstarpu-1.3 -Wl,--no-as-needed -lmkl_intel_lp64 \ -lmkl_sequential -lmkl_core -lpthread -lm -lrt
Note that an update of your environment variable LD_LIBRARY_PATH (DYLD_LIBRARY_PATH on Mac) with the path of the libraries could be required before executing
export LD_LIBRARY_PATH=path/to/libs:path/to/chameleon/lib
5.6. Using Chameleon
5.6.1. Using Chameleon executables
Chameleon provides several test executables that are compiled and
linked with Chameleon's dependencies. Instructions about the
arguments to give to executables are accessible thanks to the
option -[-]help or -[-]h. This set of binaries are separated into
three categories and can be found in three different directories:
- example: contains examples of API usage and more specifically the
sub-directory
lapack_to_chameleon/provides a tutorial that explains how to use Chameleon functionalities starting from a full LAPACK code, see Tutorial LAPACK to Chameleon testing: contains testing drivers to check numerical correctness and assess performance of Chameleon linear algebra routines with a wide range of parameters
./testing/chameleon_stesting -H -o gemm -t 2 -m 2000 -n 2000 -k 2000
To get the list of parameters, use the
-hor--helpoption../testing/chameleon_stesting -h
Available algorithms for testing are:
- gels_hqr: Linear least squares with general matrix using hierarchical reduction trees
- ormlq_hqr: Q application with hierarchical reduction trees (LQ)
- orglq_hqr: Q generation with hierarchical reduction trees (LQ)
- gelqf_hqr: General LQ factorization with hierachical reduction trees
- ormqr_hqr: Q application with hierarchical reduction trees (QR)
- orgqr_hqr: Q generation with hierarchical reduction trees (QR)
- geqrf_hqr: General QR factorization with hierachical reduction trees
- gels: Linear least squares with general matrix
- ormlq: Q application (LQ)
- orglq: Q generation (LQ)
- gelqf: General LQ factorization
- ormqr: Q application (QR)
- orgqr: Q generation (QR)
- geqrf: General QR factorization
- gesv: General linear system solve (LU without pivoting)
- getrs: General triangular solve (LU without pivoting)
- getrf: General factorization (LU without pivoting)
- potri: Symmetric positive definite matrix inversion
- lauum: Triangular in-place matrix-matrix computation for Cholesky inversion
- trtri: Triangular matrix inversion
- posv: Symmetric positive definite linear system solve (Cholesky)
- potrs: Symmetric positive definite solve (Cholesky)
- potrf: Symmetric positive definite factorization (Cholesky)
- trsm: Triangular matrix solve
- trmm: Triangular matrix-matrix multiply
- syr2k: Symmetrix matrix-matrix rank 2k update
- syrk: Symmetrix matrix-matrix rank k update
- symm: Symmetric matrix-matrix multiply
- gemm: General matrix-matrix multiply
- lascal: General matrix scaling
- tradd: Triangular matrix-matrix addition
- geadd: General matrix-matrix addition
- lantr: Triangular matrix norm
- lansy: Symmetric matrix norm
- lange: General matrix norm
- lacpy: General matrix copy
- Configuration through environment variables
Some parameters of the Chameleon library can be set to some default values through environment variables which are listed below. Note that the code itself can modify these values through calls to `CHAMELEON_Enable()`, `CHAMELEON_Disable()`, or `CHAMELEON_Set()` (see Options)
- CHAMELEON_TILE_SIZE defines the default tile size value for all algorithms. The default value is 384.
- CHAMELEON_INNER_BLOCK_SIZE defines the default inner blocking size value for algorithms that requires it (mainly QR/LQ algorithms). The default value is 48.
- CHAMELEON_HOUSEHOLDER_MODE changes the basic QR algorithm from a flat tree (1, ChamFlatHouseholder or Flat) to an Householder tree (2, ChamTreeHouseholder, or Tree ). The default value is ChamFlatTree.
- CHAMELEON_HOUSEHOLDER_SIZE defines the size of the local housholder trees if the Houselmoder tree mode is set. The default value is 4.
- CHAMELEON_TRANSLATION_MODE defines the translation used in the LAPACK API routines. 1, In, or ChamInPlace sets the in-place translation to avoid copies. 2, Out, ChamOutOfPlace sets the out-of-place translation that uses a copy of the matrix. The default is ChamInPlace.
- CHAMELEON_GENERIC, if ON all algorithms using specialized algorithms specific to data distributions are disabled.
- CHAMELEON_AUTOMINMAX, if ON the minimal/maximal limits of tasks that can be submitted to the runtime system are set. These limits are computed per algorithm using the lookahead parameter. (StarPU specific, and currently only available for getrf)
- CHAMELEON_LOOKAHEAD defines the number of steps that will be submitted in advance in algorithms using lookahead techniques. The default is 1.
- CHAMELEON_WARNINGS enables/disables the warning output
- CHAMELEON_PARALLEL_KERNEL enables/disables the use of multi-threaded kernels. Available only for StarPU runtime system.
- CHAMELEON_GENERATE_STATS enables the profiling information of the kernels (StarPU specific)
- CHAMELEON_PROGRESS enables the progress function to show the percentage of tasks completed.
- Execution trace using EZTrace
EZTrace can be used by chameleon to generate traces. Two modules are automatically generated as soon as EZTrace is detected on the system. The first one (which is recommended) is the
chameleon_tcoremodule. It traces all theTCORE_...()functions that are called by the codelets of all the runtime but PaRSEC. The second one is thechameleon_coremodule which traces the lower levelCORE_...()functions. If using PaRSEC, you need to use this module to generate the traces.To generate traces with EZTrace, you need first to compile with -DBUILD_SHARED_LIBS=ON. EZTrace is using weak symbols to overload function calls with ld_preload and enable trace generation. Then, either you install the
libeztrace-*.sofiles into the EZTrace install directory, or you can add the path of the modules to your environementexport EZTRACE_LIBRARY_PATH=/path/to/your/modules
To check if the modules are available you should have
$ eztrace_avail 1 omp Module for OpenMP parallel regions 2 pthread Module for PThread synchronization functions (mutex, semaphore, spinlock, etc.) 3 stdio Module for stdio functions (read, write, select, poll, etc.) 4 mpi Module for MPI functions 5 memory Module for memory functions (malloc, free, etc.) 6 papi Module for PAPI Performance counters 128 chameleon_core Module for Chameleon CORE functions 129 chameleon_tcore Module for Chameleon TCORE functions
Then, you can restrict the modules used during the execution
export EZTRACE_TRACE="mpi chameleon_tcore"
The module
mpiis required if you want to run in distributed.The setup can be checked with
eztrace_loaded$ eztrace_loaded 4 mpi Module for MPI functions 129 chameleon_tcore Module for Chameleon TCORE functions
To generate the traces, you need to run your binary through eztrace:
eztrace ./chameleon_dtesting -o gemm -n 1000 -b 200 mpirun -np 4 eztrace ./chameleon_dtesting -o gemm -n 1000 -b 200 -P 2
Convert the binary files into a
.tracefile, and visualize it.eztrace_convert <username>_eztrace_log_rank_<[0-9]*> vite eztrace_output.trace
For more information on EZTrace, you can follow the support page.
- Execution trace using StarPU/FxT
StarPU can generate its own trace log files by compiling it with the
--with-fxtoption at the configure step (you can have to specify the directory where you installed FxT by giving--with-fxt=...instead of--with-fxtalone). In addition, the environment variable STARPU_FXT_TRACE must be set to 1.export STARPU_FXT_TRACE=1
And passing the
-Toption to thechameleon_xtestingprogram. By doing so, traces are generated after each execution of a program which uses StarPU in the directory pointed by the STARPU_FXT_PREFIX environment variable (if not set the default path is tmp).export STARPU_FXT_PREFIX=/home/jdoe/fxt_files/
When executing a
./testing/...Chameleon program, if it has been enabled (StarPU compiled with FxT), the program will generate trace files in the directory $STARPU_FXT_PREFIX.To save only some specific types of events the variable STARPU_FXT_EVENTS.
Finally, to generate the trace file which can be opened with Vite program, you can use the starpu_fxt_tool executable of StarPU. This tool should be in the bin directory of StarPU's installation. You can use it to generate the trace file like this:
path/to/your/install/starpu/bin/starpu_fxt_tool -i prof_filename
There is one file per mpi processus (prof_filename_0, prof_filename_1 …). To generate a trace of mpi programs you can call it like this:
path/to/your/install/starpu/bin/starpu_fxt_tool -i prof_filename*
The trace file will be named paje.trace (use -o option to specify an output name). Alternatively, for non mpi execution (only one processus and profiling file), you can set the environment variable STARPU_GENERATE_TRACE=1 to automatically generate the paje trace file.
- Use simulation mode with StarPU-SimGrid
Simulation mode can be activated by setting the cmake option CHAMELEON_SIMULATION to ON. This mode allows you to simulate execution of algorithms with StarPU compiled with SimGrid. To do so, we provide some perfmodels in the simucore/perfmodels/ directory of Chameleon sources. To use these perfmodels, please set your STARPU_HOME environment variable to
path/to/your/chameleon_sources/simucore/perfmodels. Finally, you need to set your STARPU_HOSTNAME environment variable to the name of the machine to simulate.The algorithms available for now: gemm, symm, potrf, potrs, potri, posv, getrf_nopiv, getrs_nopiv, geqrf, geqrf_hqr, gels, gels_hqr, simple and double precisions on PlaFRIM nodes with GPUs. The tile size to use depending on the platform i.e. STARPU_HOSTNAME (choose a size N multiple of the tile size):
- sirocco-k40m: 960
- sirocco-p100: 1240
- sirocco-v100: 1600
- sirocco-a100: 1600
- sirocco-rtx8000: 1600
In addition the potrf algorithm is also available on mirage and sirocco machines for the following tile sizes
- mirage: 320, 960
- sirocco: 80, 440, 960, 1440, 1920
Database of models is subject to change.
export STARPU_HOME=/tmp/chameleon/simucore/perfmodels/ export STARPU_HOSTNAME=sirocco ./testing/chameleon_dtesting -o potrf -t 22 -g 2 -n 14400 -b 1440 --nowarmup 0;dpotrf;22;2;1;1;0;1440;121;14400;14400;1804289383;0.000000e+00;7.867404e-01;1.265261e+03 export STARPU_HOSTNAME=sirocco-k40m ./testing/chameleon_stesting -o gemm -t 38 -g 2 -n 64000 -b 1600 --nowarmup 0;sgemm;38;2;1;1;0;1600;111;111;64000;64000;64000;64000;64000;64000;4.892778e-01;-1.846424e-01;1649760492;596516649;1189641421;0.000000e+00;2.010660e+01;2.607541e+04 export STARPU_HOSTNAME=sirocco-p100 ./testing/chameleon_dtesting -o geqrf -g 2 -t 30 -b 1240 -n 39680 --nowarmup 0;dgeqrf;30;2;1;1;0;1240;48;39680;39680;39680;4;1804289383;0.000000e+00;3.893336e+01;2.139677e+03
- Use out of core support with StarPU
If the matrix can not fit in the main memory, StarPU can automatically evict tiles to the disk. The following variables need to be set:
- STARPU_DISK_SWAP environment variable to a place where to store
evicted tiles, for example:
STARPU_DISK_SWAP=/tmp- STARPU_DISK_SWAP_BACKEND environment variable to the I/O method,
for example:
STARPU_DISK_SWAP_BACKEND=unistd_o_direct- STARPU_LIMIT_CPU_MEM environment variable to the amount of memory
that can be used in MBytes, for example:
STARPU_LIMIT_CPU_MEM=1000
5.6.2. Tutorial LAPACK to Chameleon
Chameleon provides routines to solve dense general systems of linear equations, symmetric positive definite systems of linear equations and linear least squares problems, using LU, Cholesky, QR and LQ factorizations. Real arithmetic and complex arithmetic are supported in both single precision and double precision. Routines that compute linear algebra are of the following form:
CHAMELEON_name[_Tile[_Async]]
- all user routines are prefixed with CHAMELEON
- in the pattern CHAMELEON_name[_Tile[_Async]], name follows the BLAS/LAPACK naming scheme for algorithms (e.g. sgemm for general matrix-matrix multiply simple precision)
- Chameleon provides three interface levels
- CHAMELEON_name: simplest interface, very close to CBLAS and LAPACKE, matrices are given following the LAPACK data layout (1-D array column-major). It involves copy of data from LAPACK layout to tile layout and conversely (to update LAPACK data), see Step1.
- CHAMELEON_name_Tile: the tile interface avoid copies between LAPACK and tile layouts. It is the standard interface of Chameleon and it should achieved better performance than the previous simplest interface. The data are given through a specific structure called a descriptor, see Step2.
- CHAMELEON_name_Tile_Async: similar to the tile interface, it avoids synchonization barrier normally called between Tile routines. At the end of an Async function, completion of tasks is not guaranteed and data are not necessarily up-to-date. To ensure that tasks have been all executed, a synchronization function has to be called after the sequence of Async functions, see Step4.
CHAMELEON routine calls have to be preceded from
CHAMELEON_Init( NCPU, NGPU );
to initialize CHAMELEON and the runtime system and followed by
CHAMELEON_Finalize();
to free some data and finalize the runtime and/or MPI.
This tutorial is dedicated to the API usage of Chameleon. The idea is to start from a simple code and step by step explain how to use Chameleon routines. The first step is a full BLAS/LAPACK code without dependencies to Chameleon, a code that most users should easily understand. Then, the different interfaces Chameleon provides are exposed, from the simplest API (step1) to more complicated ones (until step4). The way some important parameters are set is discussed in step5. step6 is an example about distributed computation with MPI. Finally step7 shows how to let Chameleon initialize user's data (matrices/vectors) in parallel.
Source files can be found in the example/lapack_to_chameleon/
directory. If CMake option CHAMELEON_ENABLE_EXAMPLE is ON then
source files are compiled with the project libraries. The
arithmetic precision is double. To execute a step
X, enter the following command:
./stepX --option1 --option2 ...
Instructions about the arguments to give to executables are
accessible thanks to the option -[-]help or -[-]h. Note there
exist default values for options.
For all steps, the program solves a linear system \(Ax=B\) The matrix values are randomly generated but ensure that matrix \(A\) is symmetric positive definite so that \(A\) can be factorized in a \(LL^T\) form using the Cholesky factorization.
The different steps of the tutorial are:
- Step0: a simple Cholesky example using the C interface of BLAS/LAPACK
- Step1: introduces the LAPACK equivalent interface of Chameleon
- Step2: introduces the tile interface
- Step3: indicates how to give your own tile matrix to Chameleon
- Step4: introduces the tile async interface
- Step5: shows how to set some important parameters
- Step6: introduces how to benefit from MPI in Chameleon
- Step7: introduces how to let Chameleon initialize the user's matrix data
- Step0
The C interface of BLAS and LAPACK, that is, CBLAS and LAPACKE, are used to solve the system. The size of the system (matrix) and the number of right hand-sides can be given as arguments to the executable (be careful not to give huge numbers if you do not have an infinite amount of RAM!). As for every step, the correctness of the solution is checked by calculating the norm \(||Ax-B||/(||A||||x||+||B||)\). The time spent in factorization+solve is recorded and, because we know exactly the number of operations of these algorithms, we deduce the number of operations that have been processed per second (in GFlops/s). The important part of the code that solves the problem is:
/* Cholesky factorization: * A is replaced by its factorization L or L^T depending on uplo */ LAPACKE_dpotrf( LAPACK_COL_MAJOR, 'U', N, A, N ); /* Solve: * B is stored in X on entry, X contains the result on exit. * Forward ... */ cblas_dtrsm( CblasColMajor, CblasLeft, CblasUpper, CblasConjTrans, CblasNonUnit, N, NRHS, 1.0, A, N, X, N); /* ... and back substitution */ cblas_dtrsm( CblasColMajor, CblasLeft, CblasUpper, CblasNoTrans, CblasNonUnit, N, NRHS, 1.0, A, N, X, N); - Step1
It introduces the simplest Chameleon interface which is equivalent to CBLAS/LAPACKE. The code is very similar to step0 but instead of calling CBLAS/LAPACKE functions, we call Chameleon equivalent functions. The solving code becomes:
/* Factorization: */ CHAMELEON_dpotrf( UPLO, N, A, N ); /* Solve: */ CHAMELEON_dpotrs(UPLO, N, NRHS, A, N, X, N);
The API is almost the same so that it is easy to use for beginners. It is important to keep in mind that before any call to CHAMELEON routines, CHAMELEON_Init has to be invoked to initialize CHAMELEON and the runtime system. Example:
CHAMELEON_Init( NCPU, NGPU );
After all CHAMELEON calls have been done, a call to CHAMELEON_Finalize is required to free some data and finalize the runtime and/or MPI.
CHAMELEON_Finalize();
We use CHAMELEON routines with the LAPACK interface which means the routines accepts the same matrix format as LAPACK (1-D array column-major). Note that we copy the matrix to get it in our own tile structures, see details about this format here Tile Data Layout. This means you can get an overhead coming from copies.
- Step2
This program is a copy of step1 but instead of using the LAPACK interface which reads to copy LAPACK matrices inside CHAMELEON routines we use the tile interface. We will still use standard format of matrix but we will see how to give this matrix to create a CHAMELEON descriptor, a structure wrapping data on which we want to apply sequential task-based algorithms. The solving code becomes:
/* Factorization: */ CHAMELEON_dpotrf_Tile( UPLO, descA ); /* Solve: */ CHAMELEON_dpotrs_Tile( UPLO, descA, descX );
To use the tile interface, a specific structure CHAM_desc_t must be created. This can be achieved from different ways.
- Use the existing function CHAMELEON_Desc_Create: means the matrix data are considered contiguous in memory as it is considered in PLASMA (Tile Data Layout).
- Use the existing function CHAMELEON_Desc_Create_OOC: means the matrix data is allocated on-demand in memory tile by tile, and possibly pushed to disk if that does not fit memory.
- Use the existing function CHAMELEON_Desc_Create_User: it is more flexible than Desc_Create because you can give your own way to access to tile data so that your tiles can be allocated wherever you want in memory, see next paragraph Step3.
- Create you own function to fill the descriptor. If you understand well the meaning of each item of CHAM_desc_t, you should be able to fill correctly the structure.
In Step2, we use the first way to create the descriptor:
CHAMELEON_Desc_Create(&descA, A, ChamRealDouble, NB, NB, NB*NB, N, N, 0, 0, N, N, 1, 1);- descA is the descriptor to create.
The second argument is a pointer to existing data. The existing data must follow LAPACK Column major layout Tile Data Layout (1-D array column-major) if CHAMELEON_Desc_Create is used to create the descriptor. The CHAMELEON_Desc_Create_User function can be used if you have data organized differently. This is discussed in the next paragraph Step3. Giving a NULL pointer means you let the function allocate memory space. This requires to copy the original data into the memory managed by the descriptor by calling:
CHAMELEON_Lap2Desc( ChamUpperLower, A, N, descA );
- The third argument of @code{Desc_Create} is the datatype (used for memory allocation).
- Fourth to eight arguments stand for respectively, the number of rows (NB), columns (NB) in each tile, the total number of values in a tile (NB*NB), the number of rows (N), and colmumns (N) in the entire matrix stored in the memory area.
- The ninth (@code{i}) and tenth (@code{j}) arguments are deprecated and should be set to 0. Their are kept for API backward compatibility.stand for respectively,
- The eleventh (@code{m}) and twelfth (@code{n}) gives the size of the matrix used in the later algorithms. These arguments are specific and used in precise cases. If you do not consider submatrices, just use the same values as for the entire matrix size.
- The last two arguments are the parameters of the 2-D block-cyclic distribution grid, see ScaLAPACK. To be able to use other data distribution over the nodes, CHAMELEON_Desc_Create_User function should be used. These should be both set to 1 if you provide the data pointer.
- Step3
This program makes use of the same interface than Step2 (tile interface) but does not allocate LAPACK matrices anymore so that no copy between LAPACK matrix layout and tile matrix layout are necessary to call CHAMELEON routines. To generate random right hand-sides you can use:
/* Allocate memory and initialize descriptor B */ CHAMELEON_Desc_Create(&descB, NULL, ChamRealDouble, NB, NB, NB*NB, N, NRHS, 0, 0, N, NRHS, 1, 1); /* generate RHS with random values */ CHAMELEON_dplrnt_Tile( descB, 5673 );The other important point is that is it possible to create a descriptor, the necessary structure to call CHAMELEON efficiently, by giving your own pointer to tiles if your matrix is not organized as a 1-D array column-major. This can be achieved with the CHAMELEON_Desc_Create_User routine. Here is an example:
CHAMELEON_Desc_Create_User(&descA, matA, ChamRealDouble, NB, NB, NB*NB, N, N, 0, 0, N, N, 1, 1, user_getaddr_arrayofpointers, user_getblkldd_arrayofpointers, user_getrankof_zero, NULL);Firsts arguments are the same than CHAMELEON_Desc_Create routine. Following arguments allows you to give pointer to functions that manage the access to tiles from the structure given as second argument. Here for example, matA is an array containing addresses to tiles, see the function allocate_tile_matrix defined in step3.h. If you want the matrix to be allocate by Chameleon, you can use the CHAMELEON_MAT_ALLOC_GLOBAL, or the CHAMELEON_MAT_ALLOC_TILE variables to allocate repectively as a single large allocation, or to allocate tile by tile as late as possible. The three functions you have to define for Desc_Create_User are:
- a function that returns address of tile \(A(m,n)\), m and n standing for the indexes of the tile in the global matrix. Lets consider a matrix @math{4x4} with tile size 2x2, the matrix contains four tiles of indexes: \(A(m=0,n=0)\), \(A(m=0,n=1)\), \(A(m=1,n=0)\), \(A(m=1,n=1)\)
- a function that returns the leading dimension of tile \(A(m,*)\)
- a function that returns MPI rank of tile \(A(m,n)\)
- a pointer to a structure that these three functions can use to store additional data.
Examples for these functions are visible in step3.h. Note that the way we define these functions is related to the tile matrix format and to the data distribution considered. This example should not be used with MPI since all tiles are affected to processus 0, which means a large amount of data will be potentially transfered between nodes.
- Step4
This program is a copy of step2 but instead of using the tile interface, it uses the tile async interface. The goal is to exhibit the runtime synchronization barriers. Keep in mind that when the tile interface is called, like CHAMELEON_dpotrf_Tile, a synchronization function, waiting for the actual execution and termination of all tasks, is called to ensure the proper completion of the algorithm (i.e. data are up-to-date). The code shows how to exploit the async interface to pipeline subsequent algorithms so that less synchronisations are done. The code becomes:
/* Cham structure containing parameters and a structure to interact with * the Runtime system */ CHAM_context_t *chamctxt; /* CHAMELEON sequence uniquely identifies a set of asynchronous function calls * sharing common exception handling */ RUNTIME_sequence_t *sequence = NULL; /* CHAMELEON request uniquely identifies each asynchronous function call */ RUNTIME_request_t request = CHAMELEON_REQUEST_INITIALIZER; int status; ... chameleon_sequence_create(chamctxt, &sequence); /* Factorization: */ CHAMELEON_dpotrf_Tile_Async( UPLO, descA, sequence, &request ); /* Solve: */ CHAMELEON_dpotrs_Tile_Async( UPLO, descA, descX, sequence, &request); /* Synchronization barrier (the runtime ensures that all submitted tasks * have been terminated */ RUNTIME_barrier(chamctxt); /* Ensure that all data processed on the gpus we are depending on are back * in main memory */ RUNTIME_desc_getoncpu(descA); RUNTIME_desc_getoncpu(descX); status = sequence->status;
Here the sequence of dpotrf and dpotrs algorithms is processed without synchronization so that some tasks of dpotrf and dpotrs can be concurently executed which could increase performances. The async interface is very similar to the tile one. It is only necessary to give two new objects RUNTIME_sequence_t and RUNTIME_request_t used to handle asynchronous function calls.

Figure 4: POTRI (POTRF, TRTRI, LAUUM) algorithm with and without synchronization barriers, courtesey of the PLASMA team.
- Step5
Step5 shows how to set some important parameters. This program is a copy of Step4 but some additional parameters are given by the user. The parameters that can be set are:
- number of Threads
number of GPUs
The number of workers can be given as argument to the executable with
--threads=and--gpus=options. It is important to notice that we assign one thread per gpu to optimize data transfer between main memory and devices memory. The number of workers of each type CPU and CUDA must be given at CHAMELEON_Init.if ( iparam[IPARAM_THRDNBR] == -1 ) { get_thread_count( &(iparam[IPARAM_THRDNBR]) ); /* reserve one thread par cuda device to optimize memory transfers */ iparam[IPARAM_THRDNBR] -=iparam[IPARAM_NCUDAS]; } NCPU = iparam[IPARAM_THRDNBR]; NGPU = iparam[IPARAM_NCUDAS]; /* initialize CHAMELEON with main parameters */ CHAMELEON_Init( NCPU, NGPU );- matrix size
- number of right-hand sides
block (tile) size
The problem size is given with
--n=and--nrhs=options. The tile size is given with option--nb=. These parameters are required to create descriptors. The size tile NB is a key parameter to get performances since it defines the granularity of tasks. If NB is too large compared to N, there are few tasks to schedule. If the number of workers is large this leads to limit parallelism. On the contrary, if NB is too small (i.e. many small tasks), workers could not be correctly fed and the runtime systems operations could represent a substantial overhead. A trade-off has to be found depending on many parameters: problem size, algorithm (drive data dependencies), architecture (number of workers, workers speed, workers uniformity, memory bus speed). By default it is set to 128. Do not hesitate to play with this parameter and compare performances on your machine.inner-blocking size
The inner-blocking size is given with option
--ib=. This parameter is used by kernels (optimized algorithms applied on tiles) to perform subsequent operations with data block-size that fits the cache of workers. Parameters NB and IB can be given with CHAMELEON_Set function:CHAMELEON_Set(CHAMELEON_TILE_SIZE, iparam[IPARAM_NB] ); CHAMELEON_Set(CHAMELEON_INNER_BLOCK_SIZE, iparam[IPARAM_IB] );
- Step6
This program is a copy of Step5 with some additional parameters to be set for the data distribution. To use this program properly CHAMELEON must use StarPU Runtime system and MPI option must be activated at configure. The data distribution used here is 2-D block-cyclic, see for example ScaLAPACK for explanation. The user can enter the parameters of the distribution grid at execution with
--p=option. Example using OpenMPI on four nodes with one process per node:mpirun -np 4 ./step6 --n=10000 --nb=320 --ib=64 --threads=8 --gpus=2 --p=2
In this program we use the tile data layout from PLASMA so that the call
CHAMELEON_Desc_Create(&descA, NULL, ChamRealDouble, NB, NB, NB*NB, N, N, 0, 0, N, N, GRID_P, GRID_Q);is equivalent to the following call
CHAMELEON_Desc_Create_User(&descA, NULL, ChamRealDouble, NB, NB, NB*NB, N, N, 0, 0, N, N, GRID_P, GRID_Q, chameleon_getaddr_ccrb, chameleon_getblkldd_ccrb, chameleon_getrankof_2d, NULL);functions chameleon_getaddr_ccrb, chameleon_getblkldd_ccrb, chameleon_getrankof_2d being used in Desc_Create. It is interesting to notice that the code is almost the same as Step5. The only additional information to give is the way tiles are distributed through the third function given to CHAMELEON_Desc_Create_User. Here, because we have made experiments only with a 2-D block-cyclic distribution, we have parameters P and Q in the interface of Desc_Create but they have sense only for 2-D block-cyclic distribution and then using chameleon_getrankof_2d function. Of course it could be used with other distributions, being no more the parameters of a 2-D block-cyclic grid but of another distribution. And the last parameter
void* get_rankof_argof CHAMELEON_Desc_Create_User can be used to get custom data in the get_rankof function. - Step7
This program is a copy of step6 with some additional calls to build a matrix from within chameleon using a function provided by the user. This can be seen as a replacement of the function like CHAMELEON_dplgsy_Tile() that can be used to fill the matrix with random data, CHAMELEON_dLapack_to_Tile() to fill the matrix with data stored in a lapack-like buffer, or CHAMELEON_Desc_Create_User() that can be used to describe an arbitrary tile matrix structure. In this example, the build callback function are just wrapper towards CORE_xxx() functions, so the output of the program step7 should be exactly similar to that of step6. The difference is that the function used to fill the tiles is provided by the user, and therefore this approach is much more flexible.
The new function to understand is CHAMELEON_map_Tile, e.g.
struct data_pl data_A={(double)N, 51}; CHAMELEON_map_Tile(ChamW, ChamUpperLower, descA, Cham_map_plgsy, (void*)&data_A);The idea here is to let Chameleon fill the matrix data in a task-based fashion (parallel) by using a function given by the user. First, the user has to give the access mode to the matrix between: ChamR, *ChamW, ChamRW depending on the kind of operations the callback function needs to do on the tiles. In our example here we fill the matrix with random values for the first time so that we use the access mode ChamW. Second, the user should define if all the blocks must be entirelly filled or just the upper/lower part with, e.g. ChamUpperLower. We still relies on the same structure CHAM_desc_t which must be initialized with the proper parameters, by calling for example CHAMELEON_Desc_Create. Then comes the pointer to the user's function. And finally the last parameter is an opaque pointer is used to let the user give some extra data used by his function.
5.6.3. Using custom data distributions
- Interface
It is possible to provide custom data distributions to Chameleon, to go beyond the 2D block cyclic distributions. A generic interface is provided with the functions chameleon_getrankof_custom_init, chameleon_getrankof_custom_destroy and chameleon_getrankof_custom, with the following signatures:
int chameleon_getrankof_custom_init( custom_dist_t **custom_dist, const char *dist_file ); int chameleon_getrankof_custom_destroy( custom_dist_t **dist ); int chameleon_getrankof_custom( const CHAM_desc_t *desc, int m, int n );The first function is used to read a custom distribution from an external file, whose name is provided in the dist_file argument. The file format is described below. The second function can be used to destroy the custom_dist_t pointer when it is no longer useful. The last function should be used as the get_rankof argument to CHAMELEON_Desc_Create_User, together with the custom distribution obtained from chameleon_getrankof_custom_init. The typical usage is the following:
custom_dist_t* custom_dist; chameleon_getrankof_custom_init( &custom_dist, "filename" ); CHAMELEON_Desc_Create_User(&descA, NULL, ChamRealDouble, NB, NB, NB*NB, N, N, 0, 0, N, N, CHAMELEON_Comm_size(), 1, chameleon_getaddr_ccrb, chameleon_getblkldd_ccrb, chameleon_getrankof_custom, custom_dist); /* Use the descriptor */ CHAMELEON_Desc_Destroy(&descA); chameleon_getrankof_custom_destroy(&custom_dist);Since we do not use a 2D block-cyclic distribution, the values of P and Q have no importance in CHAMELEON_Desc_Create_User. However, make sure that the product of P and Q is equal to the number of processes by using the couple (CHAMELEON_Comm_size(), 1) as a replacement for (P, Q).
- File format
The custom distribution is provided by a pattern that can have any dimension, and which is repeated all over the matrix. The file format expected by chameleon_getrankof_custom_init is a simple text format, with space-separated integer values. The first two values represent the size of the pattern (number of rows \(m_d\) and number of columns \(n_d\)). Then, the function expects \(m_d * n_d\) values, where each value is the index of the process that should handle this tile. For example, the following file content would result in a 2D block-cyclic distribution with P=2 and Q=3 (it is not necessary to skip lines, but it can make the file more readable):
2 3 0 1 2 3 4 5
5.6.4. List of available routines
- Linear Algebra routines
We list the linear algebra routines of the form CHAMELEON_name[_Tile[_Async]] (name follows LAPACK naming scheme, see http://www.netlib.org/lapack/lug/node24.html) that can be used with the Chameleon library. For details about these functions please refer to the doxygen documentation. name can be one of the following:
- BLAS 2/3 routines
- gemm: matrix matrix multiply and addition
- hemm: gemm with A Hermitian
- herk: rank k operations with A Hermitian
- her2k: rank 2k operations with A Hermitian
- lauum: computes the product U * U' or L' * L, where the triangular factor U or L is stored in the upper or lower triangular part of the array A
- symm: gemm with A symmetric
- syrk: rank k operations with A symmetric
- syr2k: rank 2k with A symmetric
- trmm: gemm with A triangular
- Triangular solving routines
- trsm: computes triangular solve
- trsmpl: performs the forward substitution step of solving a system of linear equations after the tile LU factorization of the matrix
- trsmrv:
- trtri: computes the inverse of a complex upper or lower triangular matrix A
- LL' (Cholesky) routines
- posv: linear systems solving using Cholesky factorization
- potrf: Cholesky factorization
- potri: computes the inverse of a complex Hermitian positive definite matrix A using the Cholesky factorization A
- potrimm:
- potrs: linear systems solving using existing Cholesky factorization
- sysv: linear systems solving using Cholesky decomposition with A symmetric
- sytrf: Cholesky decomposition with A symmetric
- sytrs: linear systems solving using existing Cholesky decomposition with A symmetric
- LU routines
- gesv_incpiv: linear systems solving with LU factorization and partial pivoting
- gesv_nopiv: linear systems solving with LU factorization and without pivoting
- getrf_incpiv: LU factorization with partial pivoting
- getrf_nopiv: LU factorization without pivoting
- getrs_incpiv: linear systems solving using existing LU factorization with partial pivoting
- getrs_nopiv: linear systems solving using existing LU factorization without pivoting
- QR/LQ routines
- gelqf: LQ factorization
- gelqf_param: gelqf with hqr
- gelqs: computes a minimum-norm solution min || A*X - B || using the LQ factorization
- gelqs_param: gelqs with hqr
- gels: Uses QR or LQ factorization to solve a overdetermined or underdetermined linear system with full rank matrix
- gels_param: gels with hqr
- geqrf: QR factorization
- geqrf_param: geqrf with hqr
- geqrs: computes a minimum-norm solution min || A*X - B || using the RQ factorization
- hetrd: reduces a complex Hermitian matrix A to real symmetric tridiagonal form S
- geqrs_param: geqrs with hqr
- tpgqrt: generates a partial Q matrix formed with a blocked QR factorization of a "triangular-pentagonal" matrix C, which is composed of a unused triangular block and a pentagonal block V, using the compact representation for Q. See tpqrt to generate V
- tpqrt: computes a blocked QR factorization of a "triangular-pentagonal" matrix C, which is composed of a triangular block A and a pentagonal block B, using the compact representation for Q
- unglq: generates an M-by-N matrix Q with orthonormal rows, which is defined as the first M rows of a product of the elementary reflectors returned by CHAMELEON_zgelqf
- unglq_param: unglq with hqr
- ungqr: generates an M-by-N matrix Q with orthonormal columns, which is defined as the first N columns of a product of the elementary reflectors returned by CHAMELEON_zgeqrf
- ungqr_param: ungqr with hqr
- unmlq: overwrites C with Q*C or C*Q or equivalent operations with transposition on conjugate on C (see doxygen documentation)
- unmlq_param: unmlq with hqr
- unmqr: similar to unmlq (see doxygen documentation)
- unmqr_param: unmqr with hqr
- EVD/SVD
- gesvd: singular value decomposition
- heevd: eigenvalues/eigenvectors computation with A Hermitian
Specific Matrix transformation for Data Analysis
- cesca: centered-scaled matrix transformation, pretreatment algorithm for Principal Component Analysis
- gram: Gram matrix transformation, pretreatment algorithm for Multidimensional Scaling
- Extra routines
- Norms
- lange: compute norm of a matrix (Max, One, Inf, Frobenius)
- lanhe: lange with A Hermitian
- lansy: lange with A symmetric
- lantr: lange with A triangular
- Random matrices generation
- plghe: generate a random Hermitian matrix
- plgsy: generate a random symmetrix matrix
- plgtr: generate a random trapezoidal matrix
- plrnt: generate a random matrix
- plrnk: generate a random matrix of rank K with K <= min(M,N)
- Others
- geadd: general matrix matrix addition
- lacpy: copy matrix into another
- lascal: scale a matrix
- laset: copy the triangular part of a matrix into another, set a value for the diagonal and off-diagonal part
- tradd: trapezoidal matrices addition
- Map functions
- map: apply a user operator on each tile of the matrix
- Norms
In addition, all BLAS 3 routines
gemm,hemm,her2k,herk,lauum,symm,syr2k,syrk,trmm,trsmand LAPACKlacpy,lange,lanhe,lansy,lantr,laset,posv,potrf,potri,potrs,trtrican be called using an equivalent of the (C)BLAS/LAPACK(E) API. The parameters are the same and the user just has to add CHAMELEON_ to the standard name of the routine. For example, in CCHAMELEON_Init(4,0); CHAMELEON_cblas_dgemm(CblasColMajor, CblasNoTrans, CblasNoTrans, N, NRHS, N, 1.0, A, N, X, N, -1.0, B, N); CHAMELEON_Finalize();In Fortran, the function names are for example:
CHAMELEON_blas_dgemminstead ofDGEMMandCHAMELEON_lapack_dposvinstead ofDPOSV.
- BLAS 2/3 routines
- Options routines
Enable CHAMELEON feature.
int CHAMELEON_Enable (CHAMELEON_enum option);
Features that can be enabled/disabled:
- CHAMELEON_WARNINGS: printing of warning messages,
- CHAMELEON_AUTOTUNING: autotuning for tile size and inner block size (inactive),
- CHAMELEON_GENERATE_TRACE: enable/start the trace generation
- CHAMELEON_GENERATE_STATS: enable/start the kernel statistics
- CHAMELEON_PROGRESS: to print a progress status,
- CHAMELEON_GEMM3M: to enable the use of the gemm3m BLAS function.
Disable CHAMELEON feature.
int CHAMELEON_Disable (CHAMELEON_enum option);
Symmetric to CHAMELEON_Enable.
Set CHAMELEON parameter.
int CHAMELEON_Set (CHAMELEON_enum param, int value);
Parameters to be set:
- CHAMELEON_TILE_SIZE: size matrix tile,
- CHAMELEON_INNER_BLOCK_SIZE: size of tile inner block,
- CHAMELEON_HOUSEHOLDER_MODE: type of householder trees (FLAT or TREE),
- CHAMELEON_HOUSEHOLDER_SIZE: size of the groups in householder trees,
- CHAMELEON_TRANSLATION_MODE: related to the CHAMELEON_Lapack_to_Tile, see ztile.c.
Get value of CHAMELEON parameter.
int CHAMELEON_Get (CHAMELEON_enum param, int *value);
- Alternatively, Chameleon can also be configured through environment variables.
- CHAMELEON_GEMM_ALGO give the possibility to switch among multiple variants of the GEMM algorithms. These variants are GENERIC for the generic variant that should work with any configuration; SUMMA_C that works for 2D block cyclic distribution of the matrices A, B, and C with a C stationnary version; SUMMA_A and SUMMA_B are SUMMA variant of the algorithm that works for any distribution with respectively A, or *B that are stationnary. Note that the last two variants are only available with the StarPU runtime backend.
- Auxiliary routines
Reports CHAMELEON version number.
int CHAMELEON_Version (int *ver_major, int *ver_minor, int *ver_micro);
Initialize CHAMELEON: initialize some parameters, initialize the runtime and/or MPI.
int CHAMELEON_Init (int nworkers, int ncudas);
Finalyze CHAMELEON: free some data and finalize the runtime and/or MPI.
int CHAMELEON_Finalize (void);
Suspend CHAMELEON runtime to poll for new tasks, to avoid useless CPU consumption when no tasks have to be executed by CHAMELEON runtime system.
int CHAMELEON_Pause (void);
Symmetrical call to CHAMELEON_Pause, used to resume the workers polling for new tasks.
int CHAMELEON_Resume (void);
Return the MPI rank of the calling process.
int CHAMELEON_My_Mpi_Rank (void);
Return the size of the distributed computation
int CHAMELEON_Comm_size( int *size )
Return the rank of the distributed computation
int CHAMELEON_Comm_rank( int *rank )
Prepare the distributed processes for computation
int CHAMELEON_Distributed_start(void)
Clean the distributed processes after computation
int CHAMELEON_Distributed_stop(void)
Return the number of CPU workers initialized by the runtime
int CHAMELEON_GetThreadNbr()
Conversion from LAPACK layout to tile layout.
int CHAMELEON_Lapack_to_Tile (void *Af77, int LDA, CHAM_desc_t *A);
Conversion from tile layout to LAPACK layout.
int CHAMELEON_Tile_to_Lapack (CHAM_desc_t *A, void *Af77, int LDA);
- Descriptor routines
Create matrix descriptor, internal function.
int CHAMELEON_Desc_Create(CHAM_desc_t **desc, void *mat, cham_flttype_t dtyp, int mb, int nb, int bsiz, int lm, int ln, int i, int j, int m, int n, int p, int q);Create matrix descriptor, user function.
int CHAMELEON_Desc_Create_User(CHAM_desc_t **desc, void *mat, cham_flttype_t dtyp, int mb, int nb, int bsiz, int lm, int ln, int i, int j, int m, int n, int p, int q, void* (*get_blkaddr)( const CHAM_desc_t*, int, int), int (*get_blkldd)( const CHAM_desc_t*, int ), int (*get_rankof)( const CHAM_desc_t*, int, int ), void* get_rankof_arg);Create matrix descriptor for tiled matrix which may not fit memory.
int CHAMELEON_Desc_Create_OOC(CHAM_desc_t **descptr, cham_flttype_t dtyp, int mb, int nb, int bsiz, int lm, int ln, int i, int j, int m, int n, int p, int q);User's function version of CHAMELEON_Desc_Create_OOC.
int CHAMELEON_Desc_Create_OOC_User(CHAM_desc_t **descptr, cham_flttype_t dtyp, int mb, int nb, int bsiz, int lm, int ln, int i, int j, int m, int n, int p, int q, int (*get_rankof)( const CHAM_desc_t*, int, int ), void* get_rankof_arg);Destroys matrix descriptor.
int CHAMELEON_Desc_Destroy (CHAM_desc_t **desc);
Ensures that all data of the descriptor are up-to-date.
int CHAMELEON_Desc_Acquire (CHAM_desc_t *desc);
Release the data of the descriptor acquired by the application. Should be called if CHAMELEON_Desc_Acquire has been called on the descriptor and if you do not need to access to its data anymore.
int CHAMELEON_Desc_Release (CHAM_desc_t *desc);
Ensure that all data are up-to-date in main memory (even if some tasks have been processed on GPUs).
int CHAMELEON_Desc_Flush(CHAM_desc_t *desc, RUNTIME_sequence_t *sequence);
- Sequences routines
Create a sequence.
int CHAMELEON_Sequence_Create (RUNTIME_sequence_t **sequence);
Destroy a sequence.
int CHAMELEON_Sequence_Destroy (RUNTIME_sequence_t *sequence);
Wait for the completion of a sequence.
int CHAMELEON_Sequence_Wait (RUNTIME_sequence_t *sequence);
Terminate a sequence.
int CHAMELEON_Sequence_Flush(RUNTIME_sequence_t *sequence, RUNTIME_request_t *request)
5.6.5. Using the CHAMELEON_PARALLEL_WORKER interface.
The CHAMELEON_PARALLEL_WORKER interface is a extension only
available with the StarPU runtime system that allows to run
concurrently multi-threaded kernels.
A StarPU parallel worker, previously called a cluster, is a set of workers which execute a single parallel task (see StarPU Documentation).
To use this functionnality:
- StarPU must be compiled with the configure option
--enable-parallel-worker - Chameleon automatically detects if the StarPU parallel workers are available or not and can exploit them, but you need to force Chameleon to be linked with a multi-threaded BLAS library if you want the parallel workers to be able to do parallel BLAS calls. To do that, you must add
-DCHAMELEON_KERNELS_MT=ONto your cmake line.
Below are given some examples to use the couple Chameleon/StarPU to enable parallel tasks to be run concurrently. For now, this is only available for a few subset of tasks that are used in the Cholesky decomposition (POTRF, TRSM, SYRK, HERK, and GEMM) but all other algorithms using these kernels benefit from it.
- Environment variables to configure the parallel workers
CHAMELEON_PARALLEL_WORKER_LEVEL=hardware-level[:number-of-parallel-workers]
Specify the number of parallel workers per hardware-level. The default value is 1. Note that hardware-level must correspond to an hwloc machine level type (hwloc_obj_type_t) e.g.:
L2,L3,SOCKET,MACHINE.CHAMELEON_PARALLEL_WORKER_SHOW: When defined, the parallel workers contents is displayed.
- Limitations
For now, there is still an issue of bad performances with the usage of the
lwsscheduler with the parallel workers. - Examples
In the following examples,
STARPU_MAIN_THREAD_BINDis set to 1 to bind the main thread of StarPU to a dedicated CPU, subtracted from the CPU workers. This avoids using a whole parallel worker to make the submission.The machine has 64 CPUs. One is dedicated to the task submission, Two CPUs are dedicated to run the GPUs.
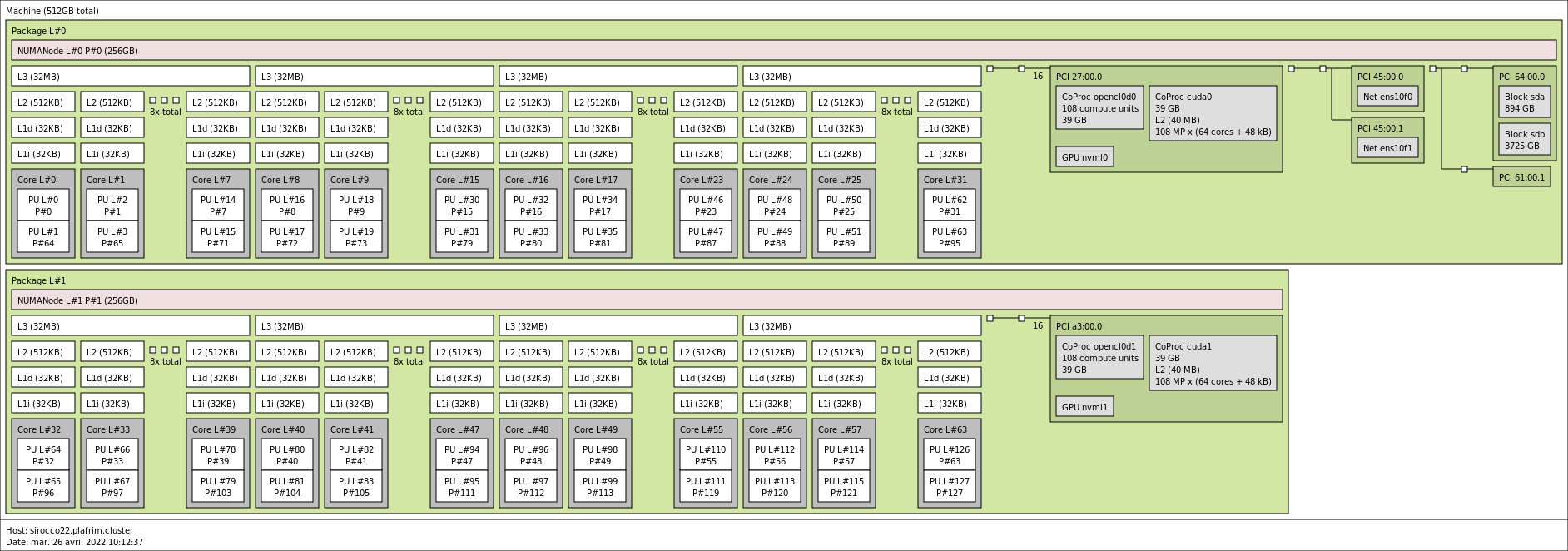
Figure 5: lstopo-sirocco24
- Example 1: Define a parallel worker per L3 cache (sirocco24)
- Here we ask StarPU to create 1 parallel worker per L3 cache. The last parallel worker does not have all the CPUs of the last L3 cache, as there are 3 dedicated CPUs.
CHAMELEON_PARALLEL_WORKER_LEVEL=L3 \ CHAMELEON_PARALLEL_WORKER_SHOW=1 \ STARPU_MAIN_THREAD_BIND=1 \ STARPU_CALIBRATE=1 \ STARPU_SCHED=dmdar \ STARPU_NWORKER_PER_CUDA=2 \ STARPU_SILENT=1 \ $PTCHAMELEON/chameleon/build/testing/chameleon_dtesting -o potrf -n 59520 -b 1440:3000:480 -g 2
Number of parallel workers created: 8 Parallel worker 0 contains the following logical indexes: 0 1 2 3 4 5 6 7 Parallel worker 1 contains the following logical indexes: 8 9 10 11 12 13 14 15 Parallel worker 2 contains the following logical indexes: 16 17 18 19 20 21 22 23 Parallel worker 3 contains the following logical indexes: 24 25 26 27 28 29 30 31 Parallel worker 4 contains the following logical indexes: 32 33 34 35 36 37 38 39 Parallel worker 5 contains the following logical indexes: 40 41 42 43 44 45 46 47 Parallel worker 6 contains the following logical indexes: 48 49 50 51 52 53 54 55 Parallel worker 7 contains the following logical indexes: 56 57 58 59 60 Id;Function;threads;gpus;P;Q;mtxfmt;nb;uplo;n;lda;seedA;tsub;time;gflops 0;dpotrf;61;2;1;1;0;1440;121;59520;59520;846930886;0.000000e+00;3.282047e+00;2.141577e+04 1;dpotrf;61;2;1;1;0;1920;121;59520;59520;1681692777;0.000000e+00;3.404408e+00;2.064605e+04 2;dpotrf;61;2;1;1;0;2400;121;59520;59520;1714636915;0.000000e+00;3.427721e+00;2.050563e+04 3;dpotrf;61;2;1;1;0;2880;121;59520;59520;1957747793;0.000000e+00;3.707147e+00;1.896001e+04 - Example 2: Define 2 parallel workers per socket (sirocco24)
- Here we ask StarPU to create 2 parallel workers per socket. This ends up with having the workers 45 and 46 in different parallel workers even though they share the same L3 cache.
CHAMELEON_PARALLEL_WORKER_LEVEL=socket:2 \ CHAMELEON_PARALLEL_WORKER_SHOW=1 \ STARPU_MAIN_THREAD_BIND=1 \ STARPU_CALIBRATE=1 \ STARPU_SCHED=dmdar \ STARPU_NWORKER_PER_CUDA=2 \ STARPU_SILENT=1 \ $PTCHAMELEON/chameleon/build/testing/chameleon_dtesting -o potrf -n 59520 -b 1440:3000:480 -g 2
Number of parallel workers created: 4 Parallel worker 0 contains the following logical indexes: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Parallel worker 1 contains the following logical indexes: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Parallel worker 2 contains the following logical indexes: 32 33 34 35 36 37 38 39 40 41 42 43 44 45 Parallel worker 3 contains the following logical indexes: 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 Id;Function;threads;gpus;P;Q;mtxfmt;nb;uplo;n;lda;seedA;tsub;time;gflops 0;dpotrf;61;2;1;1;0;1440;121;59520;59520;846930886;0.000000e+00;3.256134e+00;2.158620e+04 1;dpotrf;61;2;1;1;0;1920;121;59520;59520;1681692777;0.000000e+00;7.003285e+00;1.003637e+04 2;dpotrf;61;2;1;1;0;2400;121;59520;59520;1714636915;0.000000e+00;8.816605e+00;7.972179e+03 3;dpotrf;61;2;1;1;0;2880;121;59520;59520;1957747793;0.000000e+00;1.064581e+01;6.602370e+03
- Example 1: Define a parallel worker per L3 cache (sirocco24)
- How-to for the plafrim users
# Root directory PTCHAMELEON=~/PTCHAMELEON mkdir $PTCHAMELEON cd $PTCHAMELEON git clone git@gitlab.inria.fr:starpu/starpu.git git clone --recursive git@gitlab.inria.fr:solverstack/chameleon.git
- Setup on sirocco16 (2 cpu intel + 2 v100)
module load build/cmake/3.15.3 \ linalg/mkl/2022.0.2 \ trace/eztrace/1.1-8 \ hardware/hwloc/2.7.0 \ compiler/gcc/11.2.0 \ compiler/cuda/11.6 \ mpi/openmpi/4.0.2 \ trace/fxt/0.3.14 \ trace/eztrace/1.1-9 \ language/python # Build StarPU cd $PTCHAMELEON/starpu ./autogen.sh mkdir build && cd build # In case you want to debug take the first line #../configure --enable-debug --enable-verbose --enable-parallel-worker --disable-opencl \ # --disable-build-doc --enable-maxcpus=64 --disable-socl \ # --prefix=$PTCHAMELEON/starpu/build/install --enable-fxt # ../configure --enable-parallel-worker --disable-opencl --disable-build-doc \ --enable-maxcpus=64 --disable-socl \ --prefix=$PTCHAMELEON/starpu/build/install make -j install source $PTCHAMELEON/starpu/build/install/bin/starpu_env # Build Chameleon cd $PTCHAMELEON/chameleon mkdir build && cd build cmake .. -DBLA_VENDOR=Intel10_64lp -DCHAMELEON_KERNELS_MT=ON \ -DCHAMELEON_ENABLE_EXAMPLE=OFF -DCHAMELEON_USE_CUDA=ON make -j # test STARPU_SILENT=1 \ STARPU_SCHED=dmdar \ CHAMELEON_PARALLEL_WORKER_LEVEL=L3 \ CHAMELEON_PARALLEL_WORKER_SHOW=1 \ STARPU_MAIN_THREAD_BIND=1 \ STARPU_CUDA_PIPELINE=2 \ STARPU_NWORKER_PER_CUDA=4 \ STARPU_CALIBRATE=1 \ $PTCHAMELEON/chameleon/build/testing/chameleon_dtesting -o potrf -n 59520 -b 960:3000:480 -g 2
- Setup on sirocco24 (2 cpu amd + 2 a100)
Identical to sirocco16 except for the Intel MKL library:
module load build/cmake/3.15.3 \ linalg/mkl/2020_update4 \ trace/eztrace/1.1-8 \ hardware/hwloc/2.7.0 \ compiler/gcc/11.2.0 \ compiler/cuda/11.6 \ mpi/openmpi/4.0.2 \ trace/fxt/0.3.14 \ trace/eztrace/1.1-9 \ language/python
Strangely the execution requires the creation of links:
cd $PTCHAMELEON for lib in libmkl_gf_lp64.so libmkl_gnu_thread.so libmkl_intel_lp64.so libmkl_sequential.so ; do ln -s /cm/shared/modules/amd/rome/compiler/intel/2020_update4/mkl/lib/intel64/$lib $lib.2 done LD_LIBRARY_PATH=$PTCHAMELEON:$LD_LIBRARY_PATH
- Setup on sirocco16 (2 cpu intel + 2 v100)
5.7. Chameleon Performances on PlaFRIM
Chameleon commit: ab1fdd2820cad43250972f8d10e8a2589fb8e457.
Show performances on PlaFRIM supercomputer.
See characteristics to get details about the hardwares.
See script tools/bench/plafrim/run.sh to get details about the environment (Guix, Slurm,
etc) and the build.
Chameleon is run this way:
mpiexec -np $nmpi $CHAMELEON_BUILD/testing/chameleon_${precision}testing -o ${algorithm} -P $p -t $nthr -g $ngpu -m $m -n $n -k $k -b $b
- runtime : starpu
- precision : s or d for simple or double precision
- algorithm : gemm or potrf or geqrf_hqr
- nmpi = p x p
- nthr : depends on the node
- ngpu : depends on the node
- m = n = k
- b : depends on the node
5.7.1. bora (36 CPUs) nodes
- nmpi = 1, 4, 9
- 2D block cyclic parameters : PxQ = 1x1, 2x2 and 3x3
- Number of threads (t) = 34, one CPU being dedicated for the scheduler and one other for MPI communications
- Number of GPUs = 0
- Tile Size (b) = 280
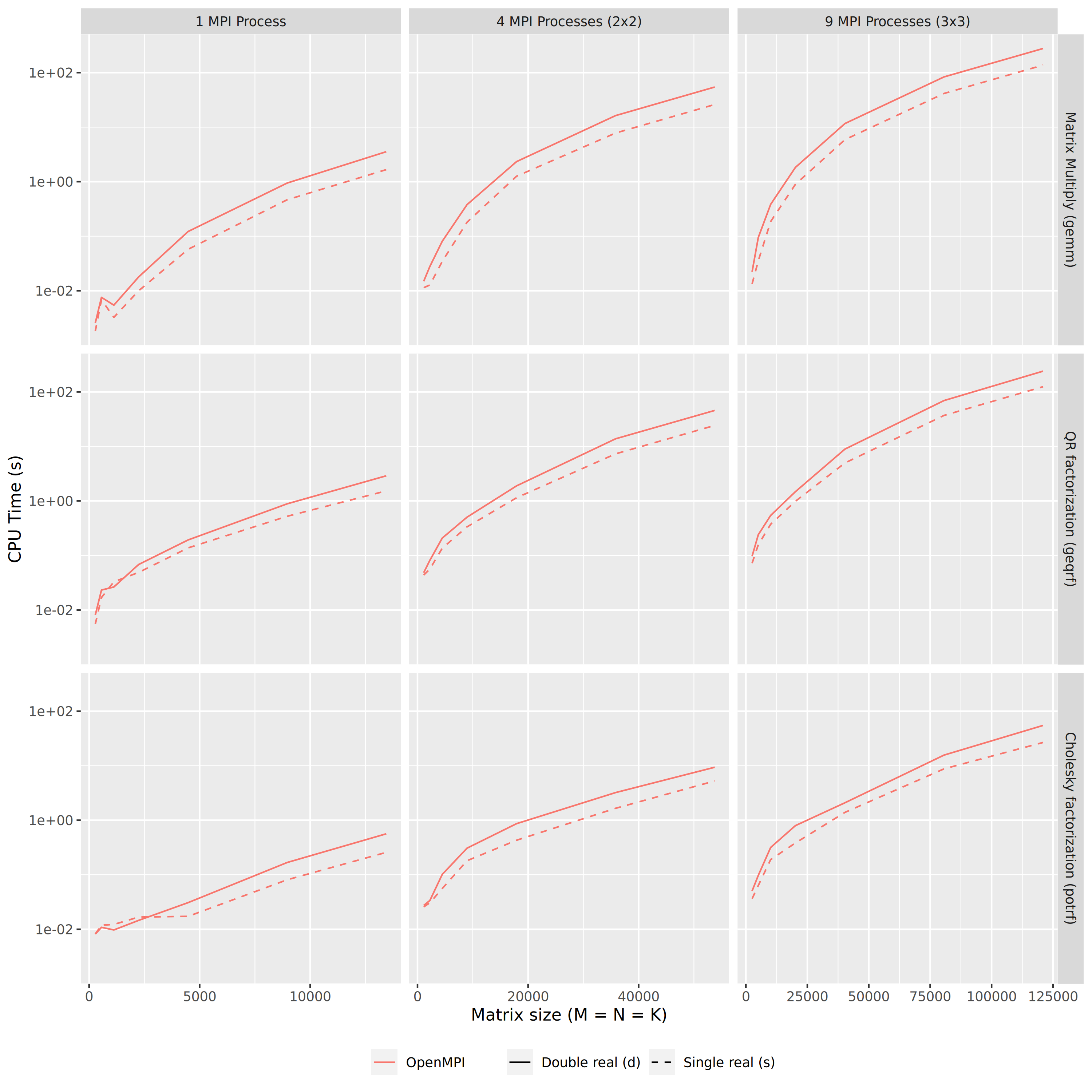
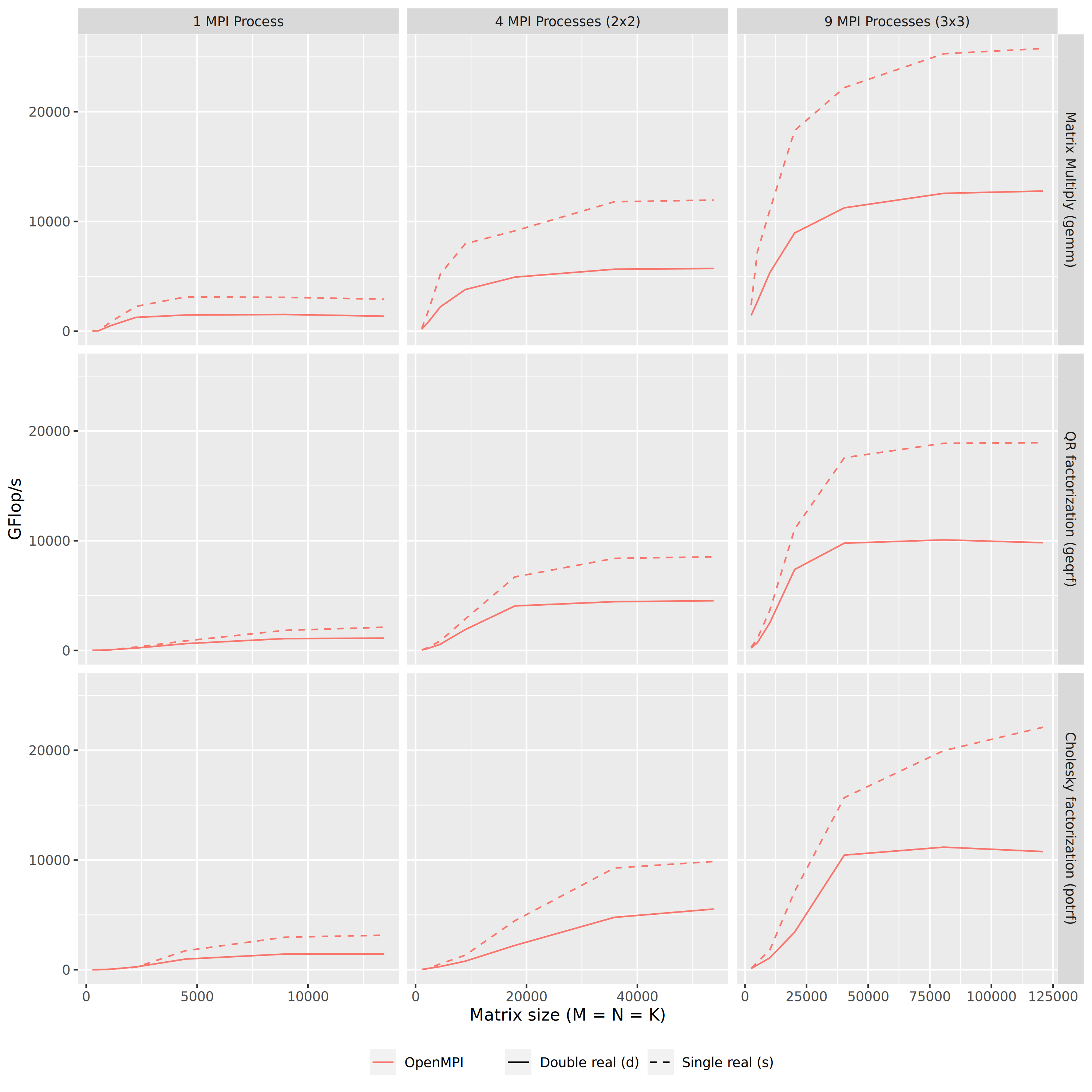
5.7.2. sirocco [14-17] (32 CPUs + 2 GPUs V100) nodes
- nmpi = 1
- 2D block cyclic parameters : PxQ = 1x1
- Number of threads (t) = 29, one CPU being dedicated for the scheduler and two others for the 2 GPUs
- Number of GPUs = 2
Tile Size (b) = 1600
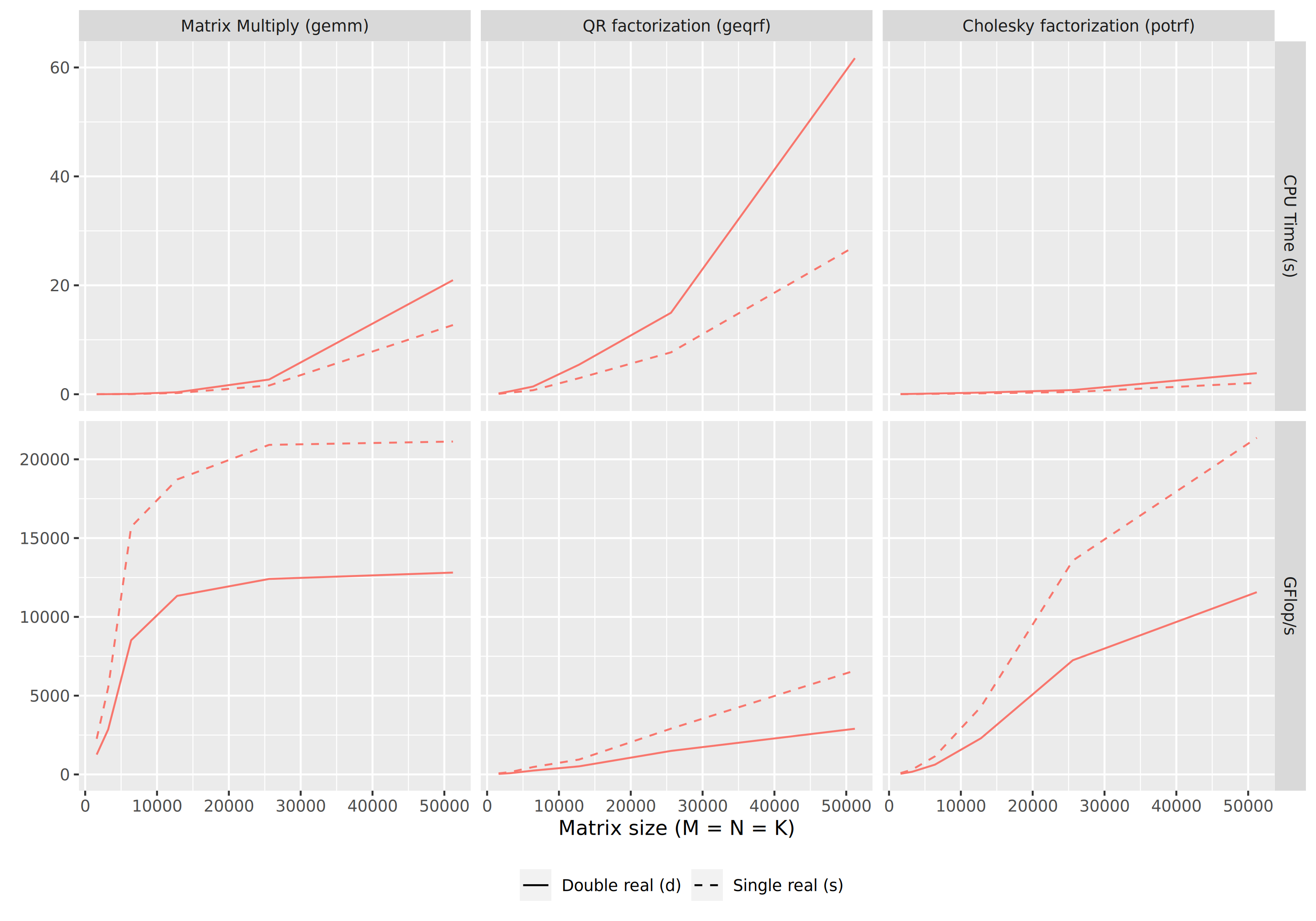
Figure 8: Performances in CPU time of GEMM, POTRF and QR on sirocco nodes
6. Tutorials
7. Contact
If you have an account on gitlab inria please submit a new issue.
If you don't have an account on gitlab inria you can send emails to chameleon-issues@inria.fr.
To get the news, register to the mailing list chameleon-announce@inria.fr (click on "S'abonner" on the left panel).
8. Contributing
8.1. To contribute to the project, you need to do it through merge request
8.1.1. Regular / Inria contributors
- Create a fork
First you need to fork the repository into your own account. You can do that simply by clicking the fork button on the gitlab interface.
https://gitlab.inria.fr/solverstack/chameleon/forks/new
Then, clone the repository on your laptop:
git clone git@gitlab.inria.fr:username/forkname.git
Once this is done, you can setup the chameleon repository as the upstream of your clone to simplify the update of your fork repository.
git remote add upstream git@gitlab.inria.fr:solverstack/chameleon.git
To update your fork with the upstream chameleon's state:
git pull upstream master git push -u origin master
- Create a "Feature" branch in your fork
To add a new feature, fix a bug, and so on, you need to create a new branch from the last state of the master branch
git branch your_branch_name git checkout your_branch_name
Apply your modifications in that "Feature" branch. Then, you need to push this branch on your online repository
git push origin your_branch_name
- Merge request
Once your branch is online, on the gitlab interface, go to the branches webpage, select the branch you want to push as a merge request, and push the button !!!
Be careful to check the 'close after merge' check box, and to push to the solverstack/chameleon repository. By default the checkbox may not be checked, and the default repository is your fork.
If the pull request is made to fix an issue, please name the branch "issueXX" so it is automatically linked to the issue. In addition, please add "fix issue #xx" in the comment of the pull request to automatically close the issue when the PR is merged.
- Rebase on top of 'master'
In some cases your "feature" branch you want to merge into "master" has a long life span so that your branch and the master branch could make some conflicts. To avoid having to handle the possible conflicts at merge request time, please rebase your "feature" on top of "master" before pushing the button merge request.
To do that, just go at the HEAD of your "feature" branch and rebase
git checkout feature git rebase master
Then force to push on your origin
git push --force origin feature
Then push the button merge request.
8.1.2. Occasional / external contributors
- Create a gitlab account
Whereas Chameleon is a public project and does not require an authentication to access it, a gitlab account is necessary to contribute. If you do not already have one, this is the first step to do.
Inria members can login directly with their Inria login in the iLDAP tab of the sign_in page.
External users need to ask for an external account, send an email to mathieu.faverge@inria.fr. Then login in the Standard tab of the sign_in page.
- Post an issue
Create a new issue (see issues) presenting your contribution proposal (feature, fix, …). The Chameleon team will set up a contribution branch for you. You can attach a patch to the issue, which we will use in this case to initiate the branch. In any case, we will then provide you with further instructions to work on the branch and eventually perform your merge request.
8.2. Configure a runner to test your branch
To be effectively merged, your branch must be tested through the gitlab-ci mechanism.
In order to execute the tests the contributor should define his own gitlab runner, e.g. his laptop or any other remote machine. To avoid having to install the proper dependencies in every runners we use the Docker image registry.gitlab.inria.fr/solverstack/docker/distrib whose recipe is defined here. Consequently, to register a compatible runner the requirements on the system are :
- OS must be Linux
Docker must be installed, e.g.
sudo apt-get update && sudo apt-get install -y curl curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo apt install -y software-properties-common sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" sudo apt-get update sudo apt install -y docker-ce sudo usermod -aG docker ${USER} newgrp docker
8.2.1. Register your runner
Please read first the Gitlab documentation for general information about runners registration.
Three steps are required:
- install the gitlab-runner program
- register your runner to your project (your fork of Chameleon)
- start gitlab-runner as a service
# install gitlab-runner sudo wget -O /usr/local/bin/gitlab-runner https://gitlab-ci-multi-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-ci-multi-runner-linux-amd64 sudo chmod +x /usr/local/bin/gitlab-runner sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash # register runner to https://gitlab.inria.fr/ sudo gitlab-runner register # see just after for an example # install and run as a service sudo gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runner sudo gitlab-runner start
Example of registering sequence:
sudo gitlab-runner register Please enter the gitlab-ci coordinator URL (e.g. https://gitlab.com/): https://gitlab.inria.fr/ Please enter the gitlab-ci token for this runner: # copy/paste the project's secret token here Please enter the gitlab-ci description for this runner: [ubuntu1604]: Please enter the gitlab-ci tags for this runner (comma separated): linux, ubuntu Whether to run untagged builds [true/false]: [false]: true Whether to lock Runner to current project [true/false]: [false]: Registering runner... succeeded runner=4jknGvoz Please enter the executor: shell, ssh, docker+machine, docker-ssh+machine, kubernetes, docker, parallels, virtualbox, docker-ssh: docker Please enter the default Docker image (e.g. ruby:2.1): ubuntu Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
8.3. To review locally a private pull request submitted by someone else
Get the patch from the pull request (Need to update that !!!! Coming from bitbucket)
curl https://bitbucket.org/api/2.0/repositories/icldistcomp/parsec/pullrequests/#PR/patch > pr#PR.patch
Then apply the patch on your local copy
git apply pr#PR.patch
10. Citing Chameleon
Feel free to use the following publications to reference Chameleon:
- Original paper that initiated Chameleon and the principles:
- Agullo, Emmanuel and Augonnet, Cédric and Dongarra, Jack and Ltaief, Hatem and Namyst, Raymond and Thibault, Samuel and Tomov, Stanimire, Faster, Cheaper, Better – a Hybridization Methodology to Develop Linear Algebra Software for GPUs, GPU Computing Gems, First Online: 17 December 2010.
- Design of the QR algorithms:
- Agullo, Emmanuel and Augonnet, Cédric and Dongarra, Jack and Faverge, Mathieu and Ltaief, Hatem and Thibault, Samuel an Tomov, Stanimire, QR Factorization on a Multicore Node Enhanced with Multiple GPU Accelerators, 25th IEEE International Parallel & Distributed Processing Symposium, First Online: 16 December 2010.
- Design of the LU algorithms:
- Agullo, Emmanuel and Augonnet, Cédric and Dongarra, Jack and Faverge, Mathieu and Langou, Julien and Ltaief, Hatem and Tomov, Stanimire, LU Factorization for Accelerator-based Systems, 9th ACS/IEEE International Conference on Computer Systems and Applications (AICCSA 11), First Online: 21 December 2011.
- Regarding distributed memory:
- Agullo, Emmanuel and Aumage, Olivier and Faverge, Mathieu and Furmento, Nathalie and Pruvost, Florent and Sergent, Marc and Thibault, Samuel, Achieving High Performance on Supercomputers with a Sequential Task-based Programming Model, Research Report, First Online: 16 June 2016.